My research focuses on advancing large multimodal systems that bridge visual perception,
representation learning, and the unification of discriminative and generative tasks in open-world
environments requiring continual learning and self-evolution.
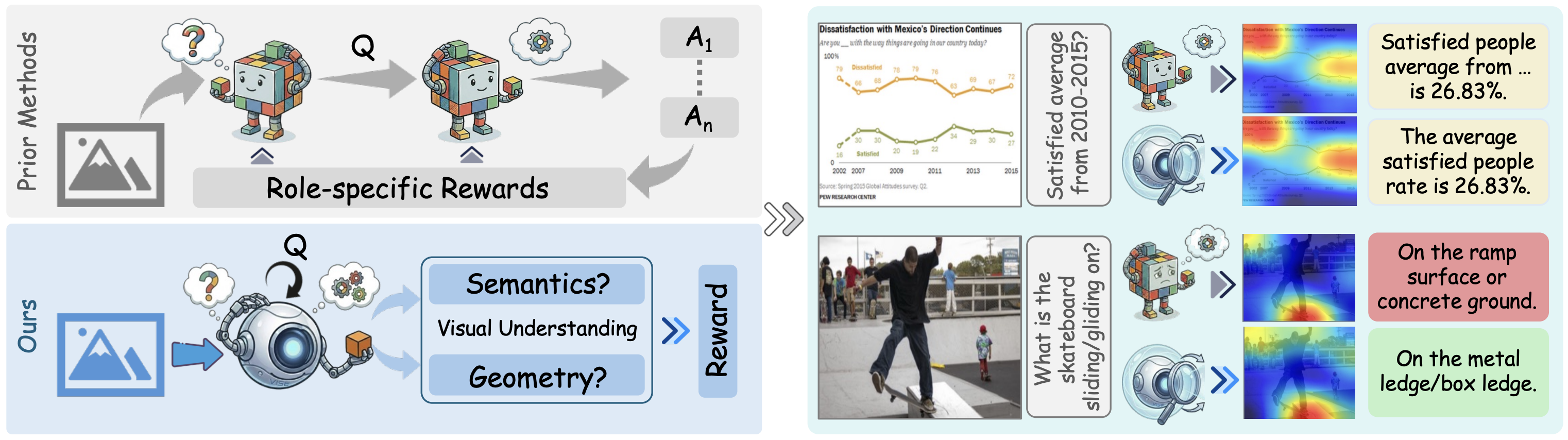
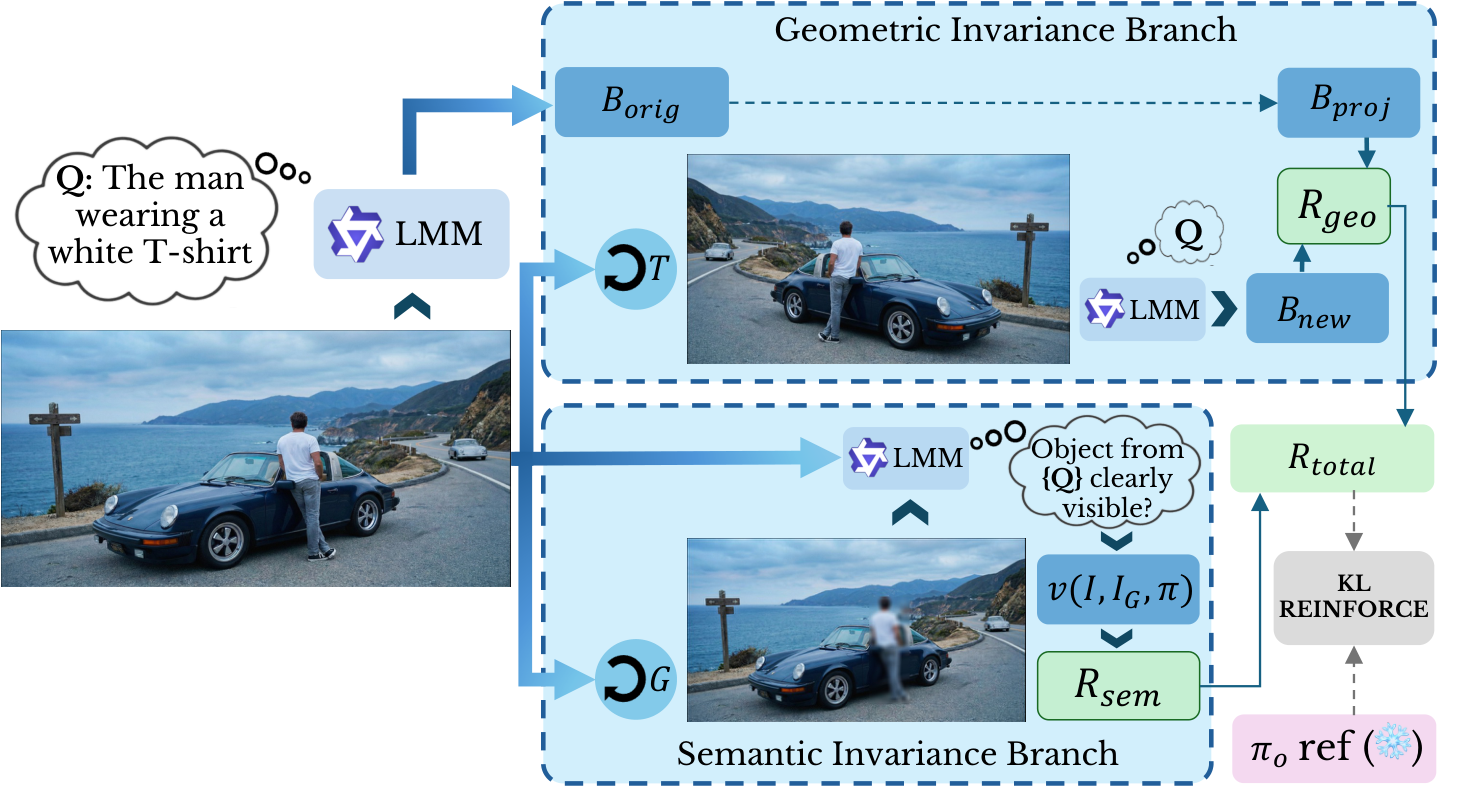
Recently, self-evolving large multimodal models (LMMs) have received attention for improving visual reasoning in a purely unsupervised setting. However, multi-role self-play and self-consistency reward schemes in existing self-evolving LMMs optimize answer agreement without ensuring the decoder attends to visual content, relying instead on statistical language priors to produce self consistent outputs. This leads to a persistent failure mode we term visual under-conditioning, where the decoder relies on language priors rather than the image during generation, manifesting as insufficient attention to visual tokens. As a result, current self-evolving LMMs struggle on vision--language understanding tasks such as image captioning and visual question answering. To address this, we propose VISE (Visual Invariance Self-Evolution), a purely unsupervised self-evolving framework that directly regularizes the model's visual conditioning policy through two complementary invariance-based rewards: a geometric invariance reward that enforces spatial consistency under known transformations, and a semantic invariance reward that penalizes evidence-agnostic generation by requiring the model to recognize the absence of evidence when predicted regions are perturbed. VISE operates within a single model without specialist roles, external reward models, or annotations, and is trained on raw unlabeled images. Experiments on 18 benchmarks demonstrate the efficacy of our approach. Using Qwen3-VL-2B as the base model, VISE achieves gains of +16.85 CIDEr on COCO and +19.66 CIDEr on TextCaps, reduces object hallucination by 5.0 Chair-I points, and generalizes across four model families and scales.
BibTeX:
@inproceedings{venkatraman2026vise,
title = {Paying More Attention to Visual Tokens in Self-Evolving Large Multimodal Models},
author = {Venkatraman, Shravan and Thawkar, Ritesh and Thawakar, Omkar and
Anwer, Rao Muhammad and Cholakkal, Hisham and Khan, Salman and Khan, Fahad Shahbaz},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2026}
}
Ask, Solve, Generate: Self-Evolving Unified Multimodal Understanding
and Generation via Self-Consistency Rewards
arXiv
A unified multimodal model that self-improves both image
understanding and generation from unlabeled images, using only self-consistency rewards.
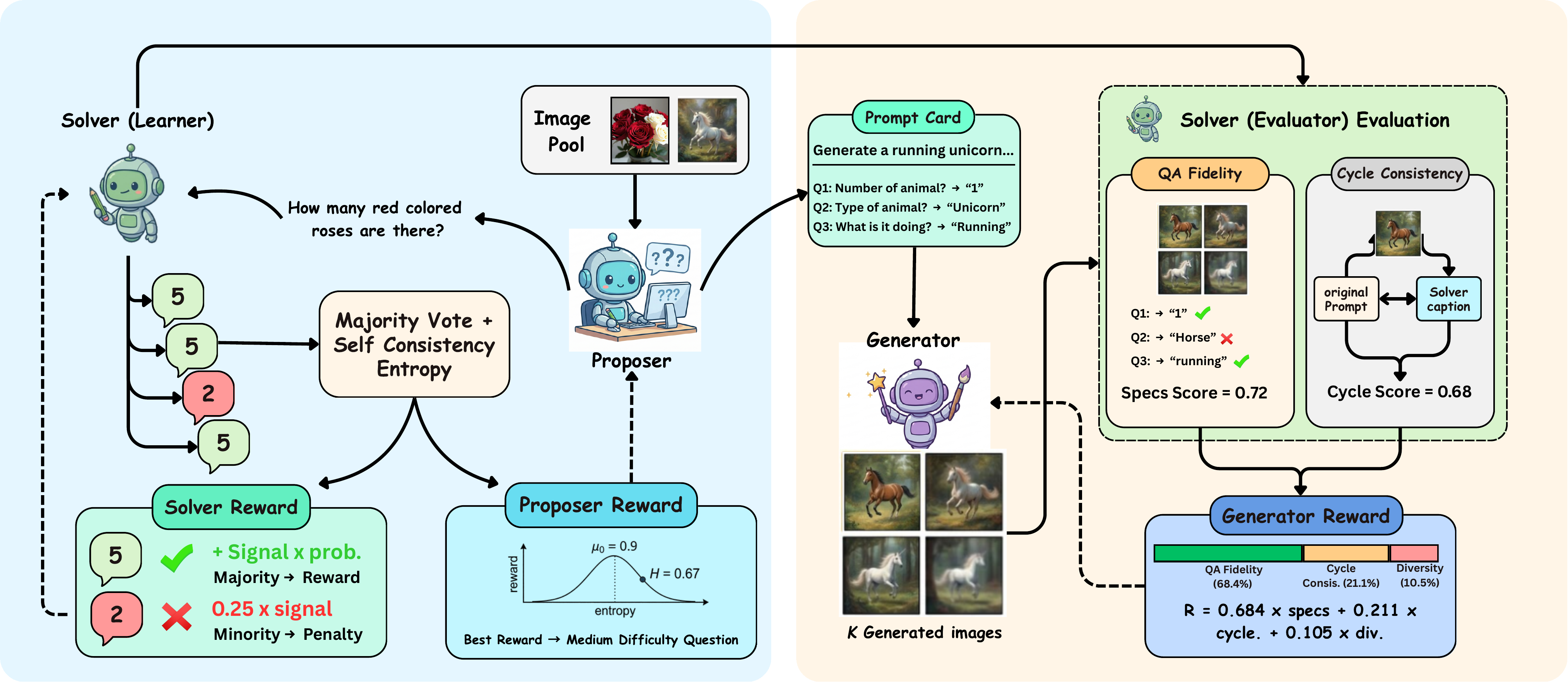
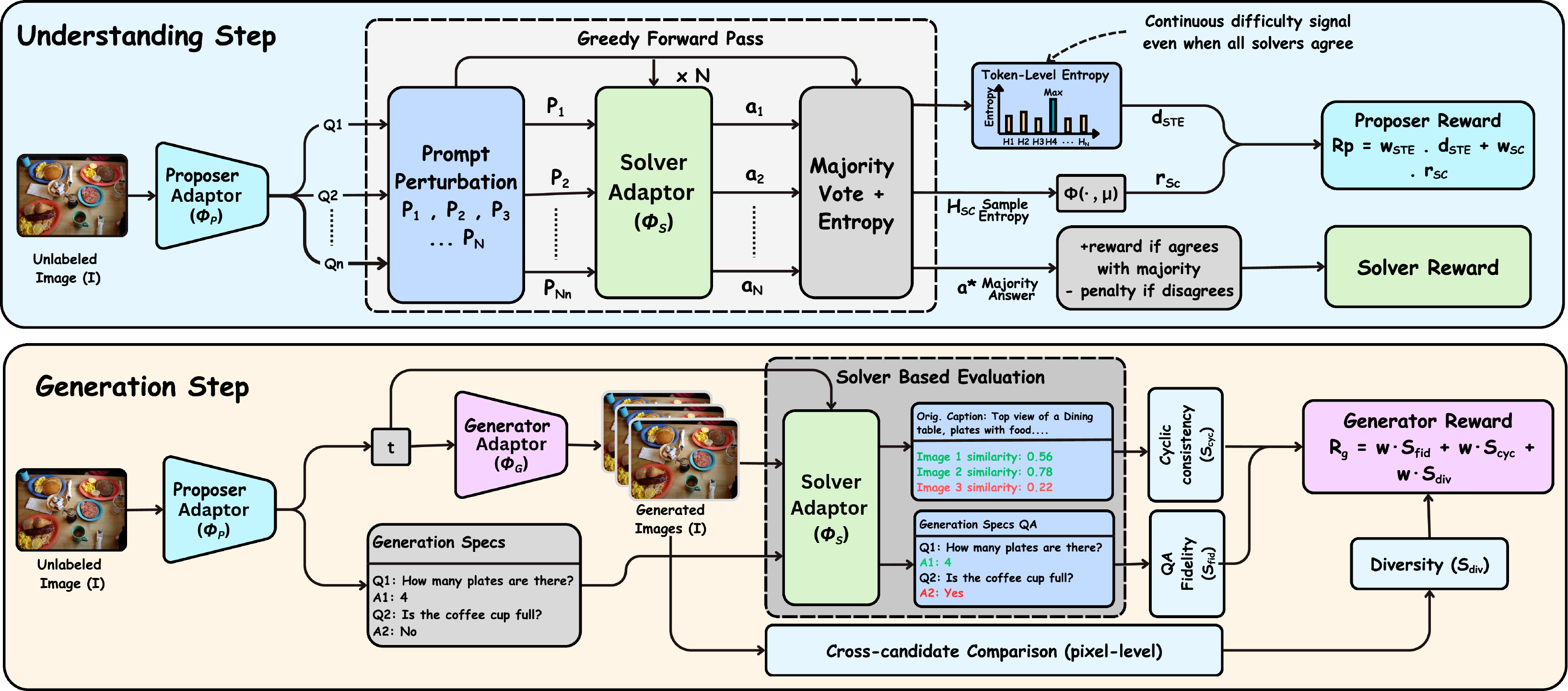
Most unified large multimodal models (LMMs) that support both visual understanding and image generation still rely on curated post-training supervision, such as human annotations, preference labels, or external reward models. We ask whether a unified LMM can improve both abilities autonomously using only unlabeled images. We propose a self-evolving training framework with three internal roles: a Proposer that generates visual questions, a Solver that answers and evaluates them, and a Generator that synthesizes images. Training uses only self-derived consistency signals, without human annotations, preference labels, or task-trained external reward/judge models. To stabilize learning, we introduce Solver Token Entropy (STE), a continuous difficulty signal based on token-level prediction uncertainty that remains useful even when sample-level consistency becomes unreliable. For image generation, we design a multi-scale internal evaluation scheme that combines question-answer fidelity scoring with cycle-consistent captioning. This creates a solver-mediated coupling, where better visual understanding enables more reliable generation assessment and stronger internal training signals. The framework preserves the same role decomposition, reward logic, and training schedule across diffusion-based BLIP3o, rectified-flow BAGEL, and autoregressive VARGPT-v1.1 architectures, requiring only each backbone's native prompting and generation interface. Across eight understanding metrics, our method consistently improves over the corresponding base models. On BAGEL, it achieves a +3.5% absolute gain on MMMU and improves GenEval image generation performance from 82% to 85%.
BibTeX:
@article{thawkar2026asksolvegenerate,
title={Ask, Solve, Generate: Self-Evolving Unified Multimodal Understanding and Generation via Self-Consistency Rewards},
author={Thawkar, Ritesh and Venkatraman, Shravan and Thawakar, Omkar and Shaker, Abdelrahman and Khan, Fahad and Cholakkal, Hisham and Khan, Salman and Anwer, Rao Muhammad},
journal={arXiv preprint arXiv:2606.27376},
year={2026}
}
2025
EvoLMM: Self-Evolving Large Multimodal Models with Continuous
Rewards
arXiv
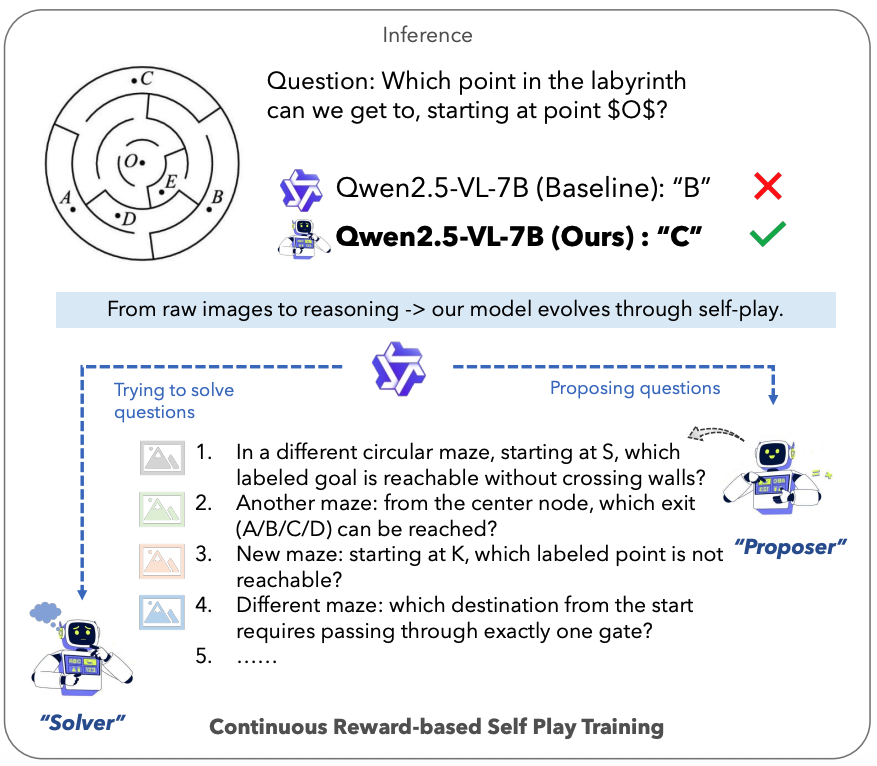
EvoLMM is a fully unsupervised self-evolving framework for LMMs that
improves visual reasoning from raw
images only, by coupling a Proposer and a Solver trained via continuous self-consistency rewards.
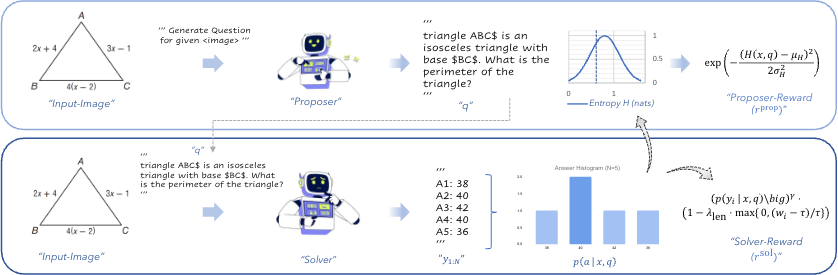
Recent advances in large multimodal models (LMMs) have enabled impressive reasoning and perception
abilities, yet most existing training pipelines still depend on human-curated data or externally
verified reward models, limiting their autonomy and scalability. In this work, we strive to improve LMM
reasoning capabilities in a purely unsupervised fashion (without any annotated data or reward
distillation). To this end, we propose a self-evolving framework, named EvoLMM, that instantiates two
cooperative agents from a single backbone model: a Proposer, which generates diverse, image-grounded
questions, and a Solver, which solves them through internal consistency, where learning proceeds through
a continuous self-rewarding process. This dynamic feedback encourages both the generation of informative
queries and the refinement of structured reasoning without relying on ground-truth or human judgments.
When using the popular Qwen2.5-VL as the base model, our EvoLMM yields consistent gains upto ∼3% on
multimodal math-reasoning benchmarks, including ChartQA, MathVista, and MathVision, using only raw
training images. We hope our simple yet effective approach will serve as a solid baseline easing future
research in self-improving LMMs in a fully-unsupervised fashion.
BibTeX:
@misc{thawakar2025evolmmselfevolvinglargemultimodal,
title={EvoLMM: Self-Evolving Large Multimodal Models with Continuous Rewards},
author={Omkat Thawakar and Shravan Venkatraman and Ritesh Thawkar and Abdelrahman Shaker and Hisham Cholakkal and Rao Muhammad Anwer and Salman Khan and Fahad Khan},
year={2025},
eprint={2511.16672},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2511.16672},
}
TIDE: Two-Stage Inverse Degradation Estimation with Guided Prior
Disentanglement for Underwater Image
Restoration
Proceedings of the IEEE/CVF Conference on Computer Vision and
Pattern Recognition (CVPR'26) Workshops [NTIRE]
Two-stage framework that adaptively restores underwater images by
identifying local degradation patterns
and applying specialized corrections through inverse degradation mapping and progressive refinement.
Underwater image restoration is essential for marine applications ranging from ecological monitoring to
archaeological surveys, but effectively addressing the complex and spatially varying nature of
underwater degradations remains a challenge. Existing methods typically apply uniform restoration
strategies across the entire image, struggling to handle multiple co-occurring degradations that vary
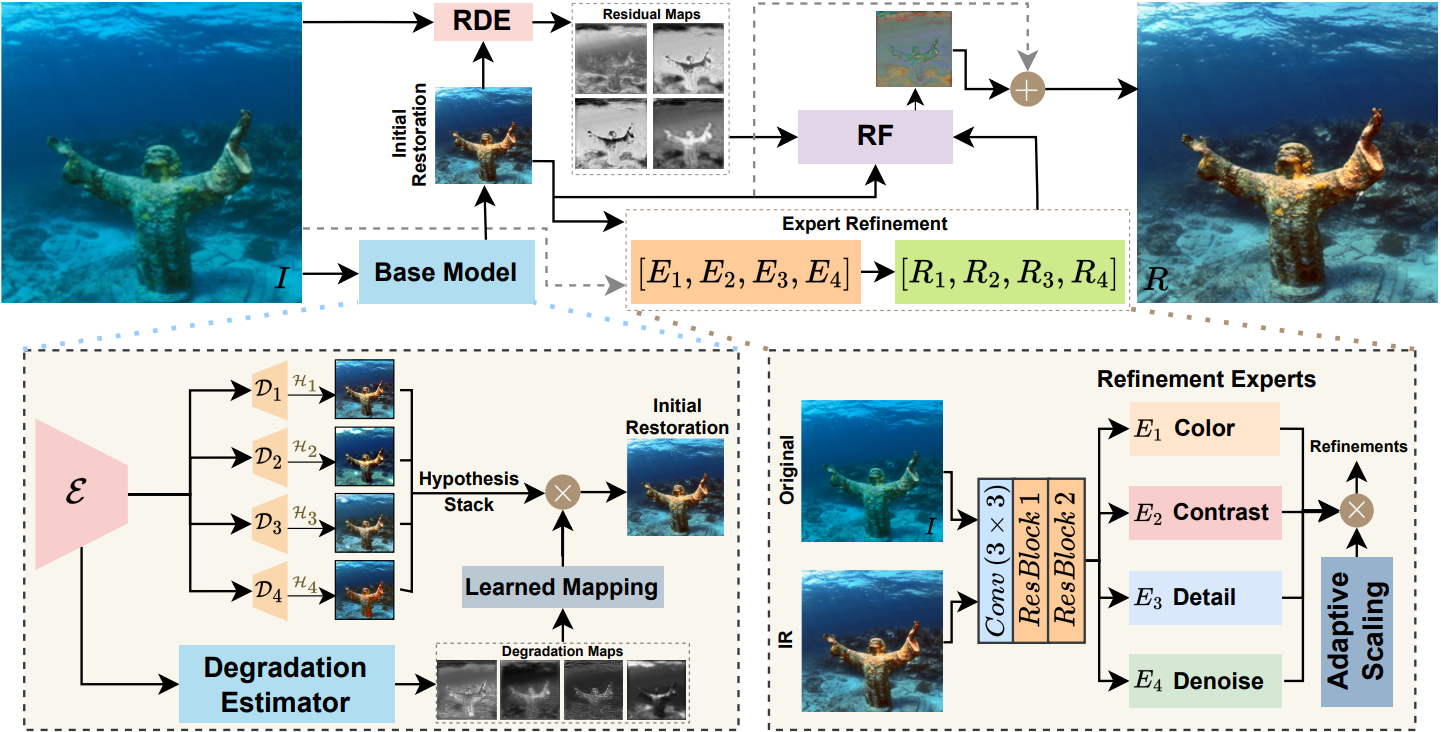
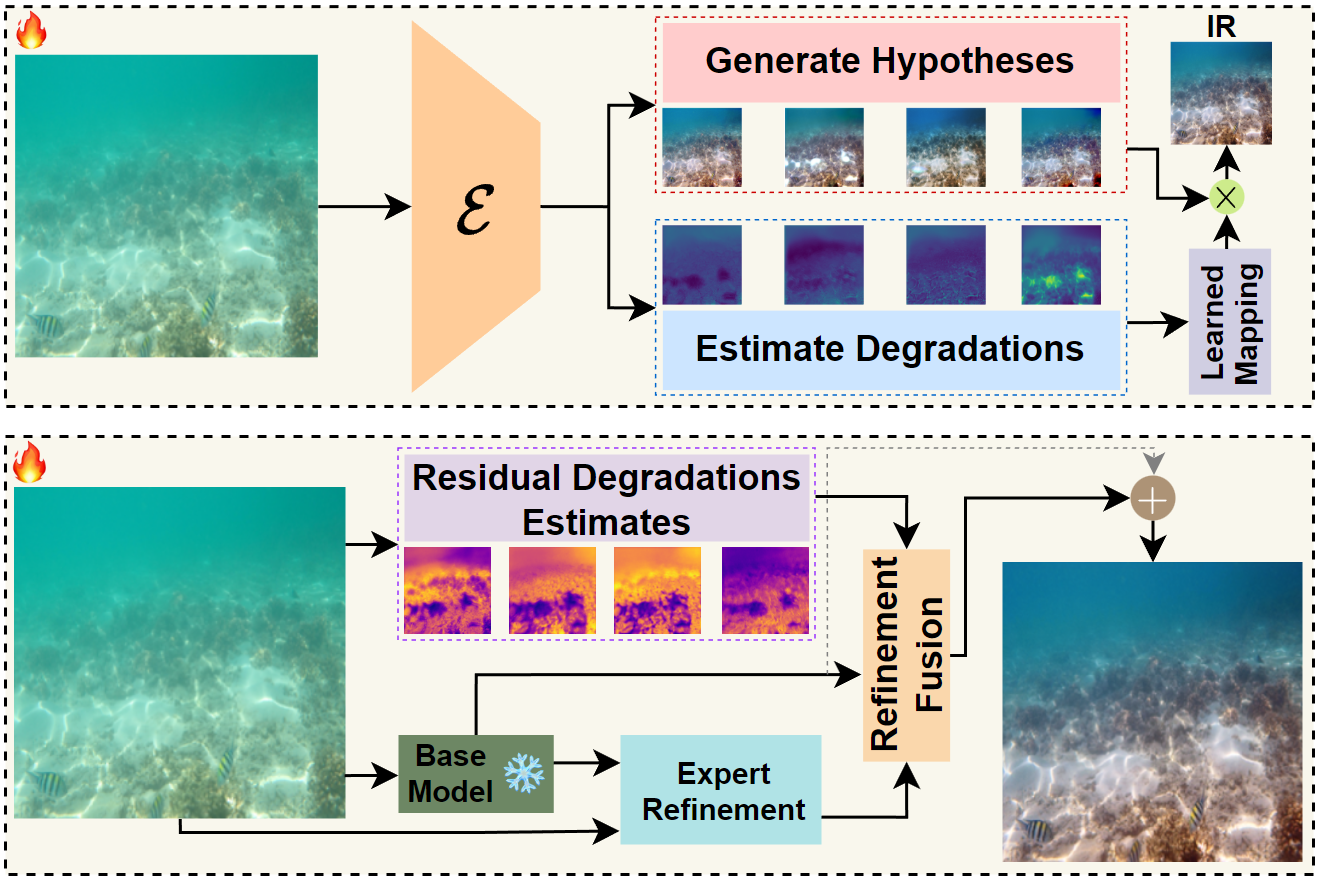
spatially and with water conditions. We introduce TIDE, a two stage inverse degradation estimation
framework that explicitly models degradation characteristics and applies targeted restoration through
specialized prior decomposition. Our approach disentangles the restoration process into multiple
specialized hypotheses that are adaptively fused based on local degradation patterns, followed by a
progressive refinement stage that corrects residual artifacts. Specifically, TIDE decomposes underwater
degradations into four key factors, namely color distortion, haze, detail loss, and noise, and designs
restoration experts specialized for each. By generating specialized restoration hypotheses, TIDE
balances competing degradation factors and produces natural results even in highly degraded regions.
Extensive experiments across both standard benchmarks and challenging turbid water conditions show that
TIDE achieves competitive performance on reference based fidelity metrics while outperforming state of
the art methods on non reference perceptual quality metrics, with strong improvements in color
correction and contrast enhancement.
BibTeX:
@inproceedings{venkatraman2026tide,
title={TIDE: Two-Stage Inverse Degradation Estimation with Guided Prior Disentanglement for Underwater Image Restoration},
author={Venkatraman, Shravan and Madavan, Rakesh Raj and Venkatesh, Pavan Kumar Sathya and Kavitha, Muthu Subash},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={2609--2619},
year={2026}
}
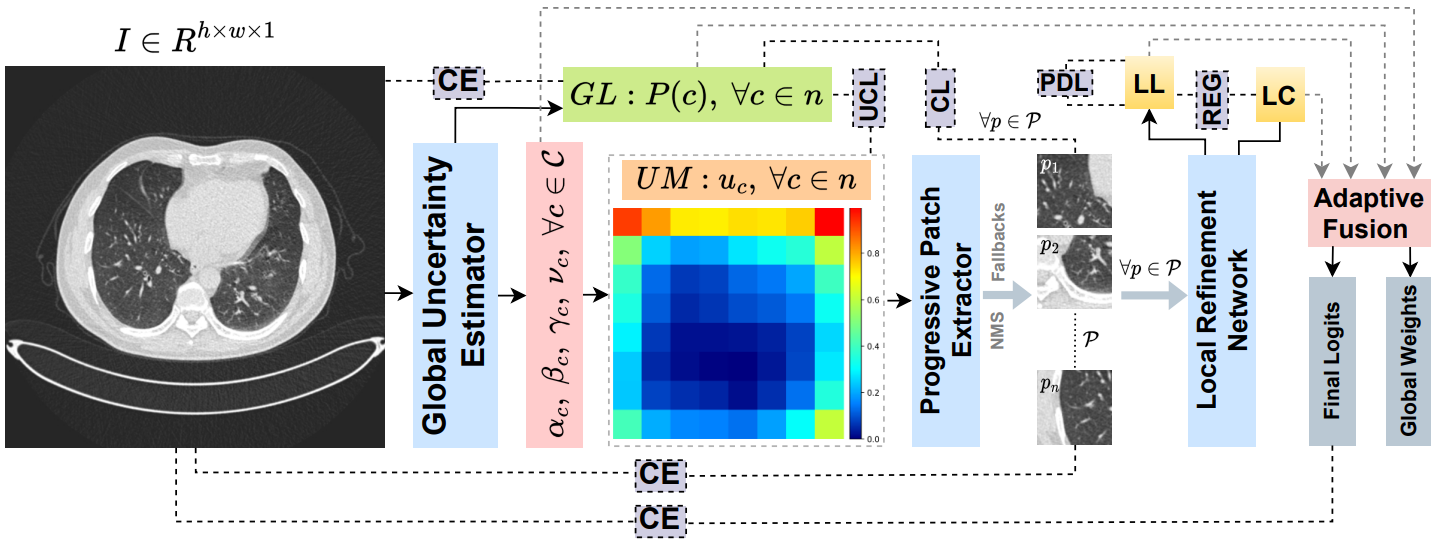
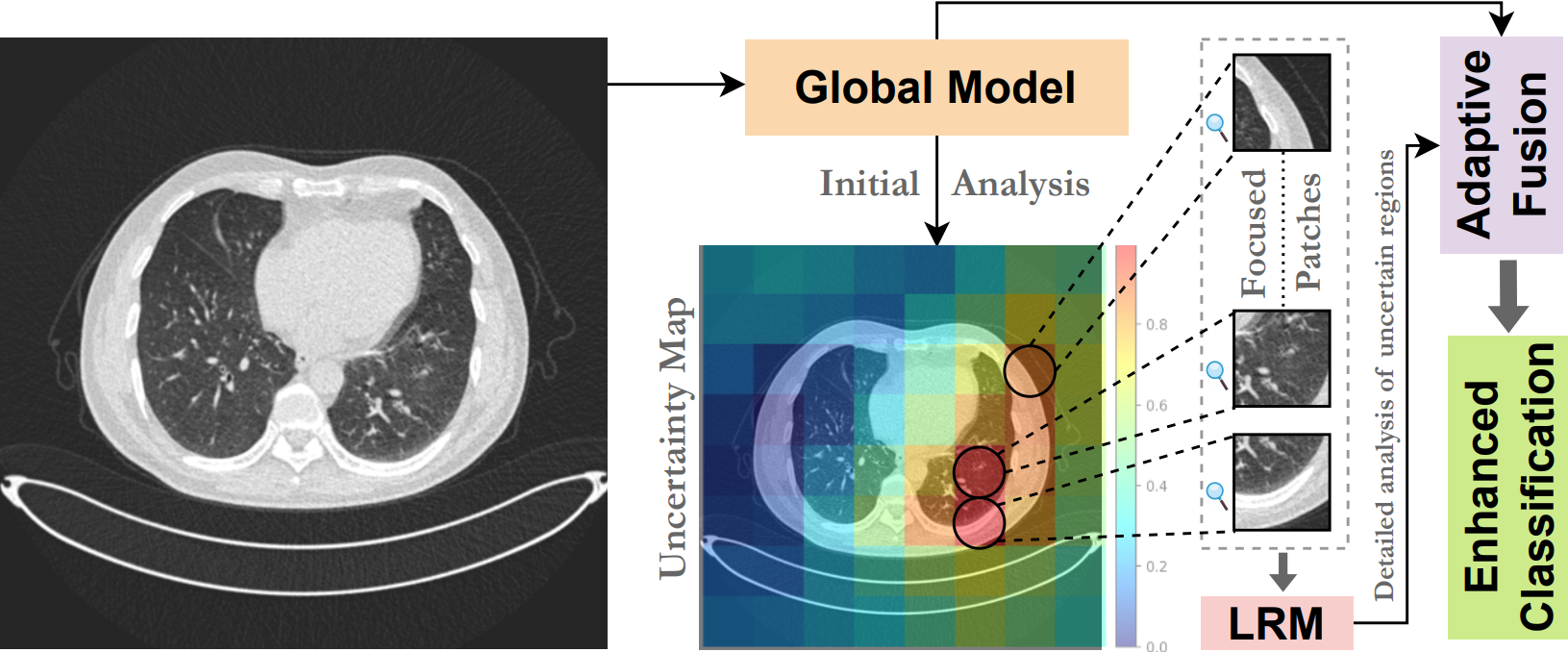
UGPL: Uncertainty-Guided Progressive Learning for Evidence-Based
Classification in Computed Tomography
Proceedings of the IEEE/CVF International Conference on Computer
Vision (ICCV'25) Workshops [CVAMD]
Guiding CT image classification by leveraging uncertainty estimates
to focus analysis on ambiguous regions
through progressive, multi-scale refinement.
Accurate classification of computed tomography (CT) images is essential for diagnosis and treatment
planning, but existing methods often struggle with the subtle and spatially diverse nature of
pathological features. Current approaches typically process images uniformly, limiting their ability to
detect localized abnormalities that require focused analysis. We introduce UGPL, an uncertainty-guided
progressive learning framework that performs a global-to-local analysis by first identifying regions of
diagnostic ambiguity and then conducting detailed examination of these critical areas. Our approach
employs evidential deep learning to quantify predictive uncertainty, guiding the extraction of
informative patches through a non-maximum suppression mechanism that maintains spatial diversity. This
progressive refinement strategy, combined with an adaptive fusion mechanism, enables UGPL to integrate
both contextual information and fine-grained details. Experiments across three CT datasets demonstrate
that UGPL consistently outperforms state-of-the-art methods, achieving improvements of 3.29%, 2.46%, and
8.08% in accuracy for kidney abnormality, lung cancer, and COVID-19 detection, respectively. Our
analysis shows that the uncertainty-guided component provides substantial benefits, with performance
dramatically increasing when the full progressive learning pipeline is implemented.
BibTeX:
@InProceedings{UGPL2025,
author = {Venkatraman, Shravan and Kumar S, Pavan and Raj, Rakesh and S, Chandrakala},
title = {UGPL: Uncertainty-Guided Progressive Learning for Evidence-Based Classification in Computed Tomography},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops},
month = {October},
year = {2025}
}
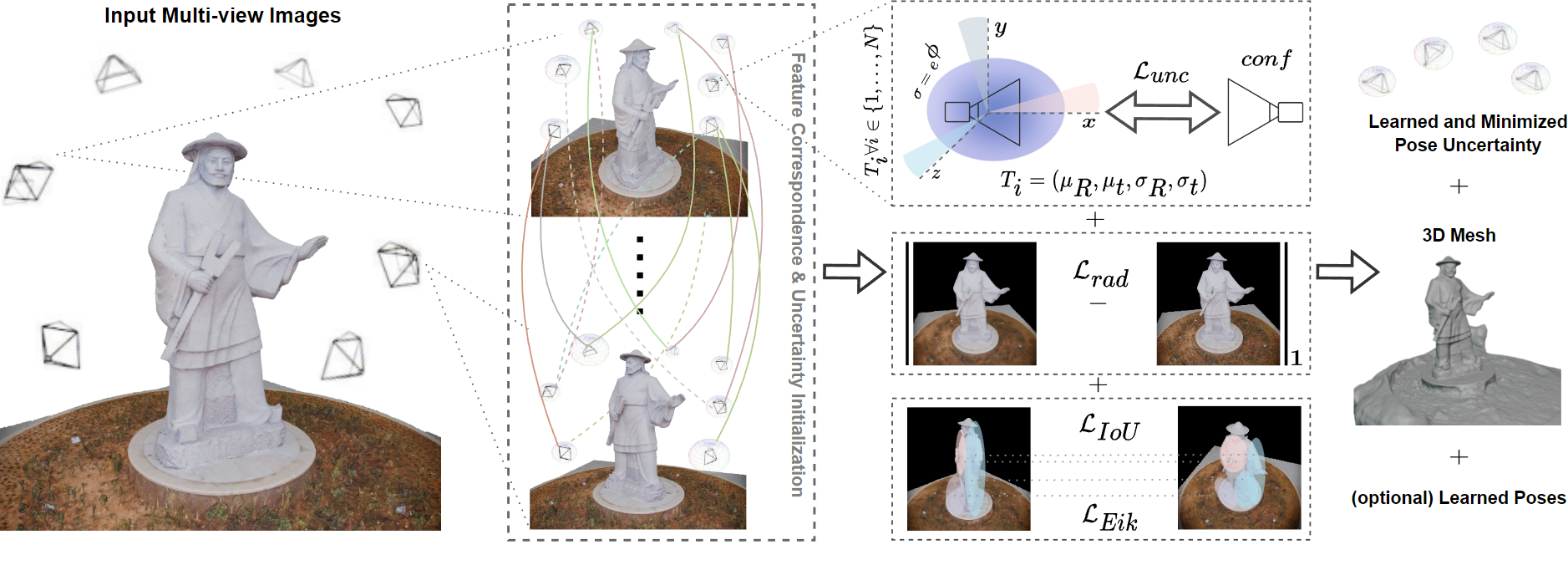
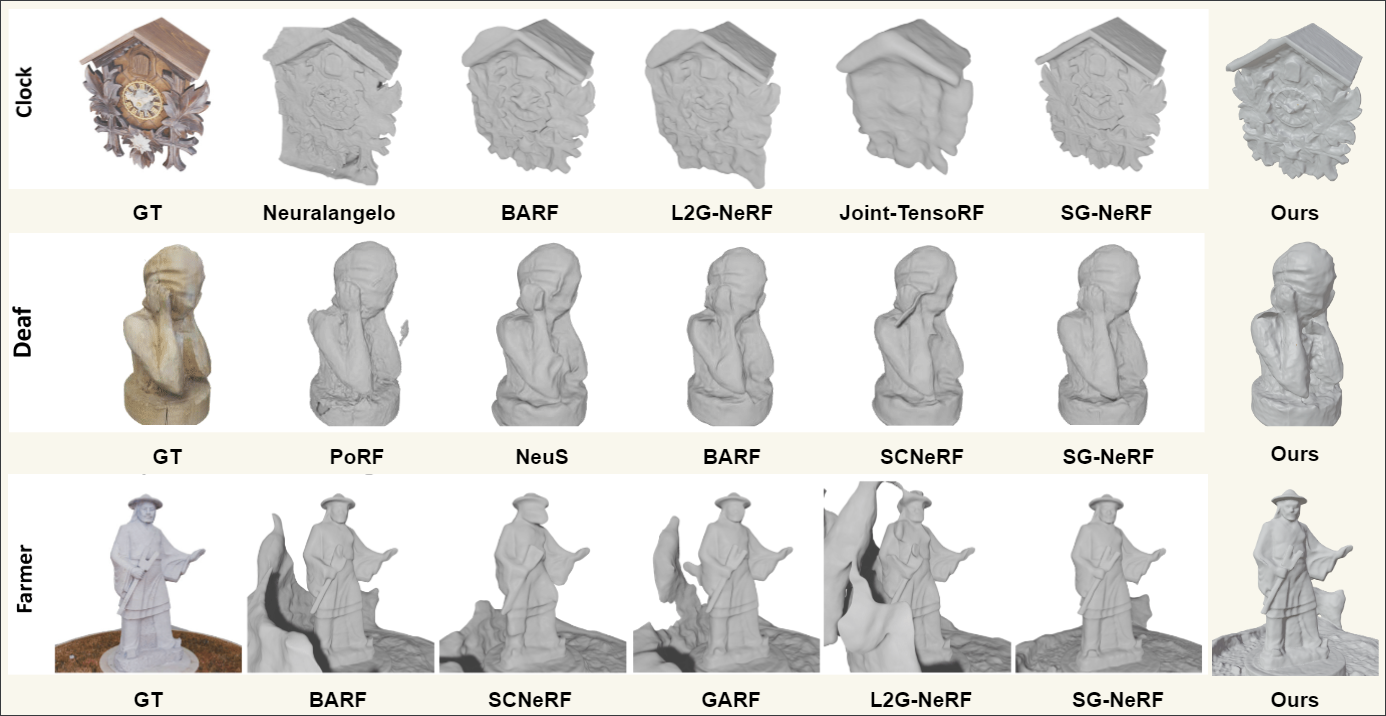
PCM-NeRF: Probabilistic Camera Modeling for Neural Radiance Fields
under Pose Uncertainty
Proceedings of the IEEE/CVF Conference on Computer Vision and
Pattern Recognition (CVPR'26) Workshops [GenRecon3D]
Explicitly modeling camera poses as probability distributions with
learnable uncertainties rather than
fixed points in SE(3) achieves high-quality reconstruction even with significant pose errors.
@inproceedings{venkatraman2026pcm,
title={PCM-NeRF: Probabilistic Camera Modeling for Neural Radiance Fields under Pose Uncertainty},
author={Venkatraman, Shravan and Madavan, Rakesh Raj and Venkatesh, Pavan Kumar Sathya},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={4719--4728},
year={2026}
}
Can We Go Beyond Visual Features? Neural Tissue Relation Modeling
for Relational Graph Analysis in
Non-Melanoma Skin Histology
Proceedings of the IEEE/CVF Conference on Computer Vision and
Pattern Recognition (CVPR'26) Workshops [PHAROS-AIF-MIH]Oral
Neural encoding of inter-tissue dependencies enables structurally
coherent predictions in boundary-dense
regions for histopathology segmentation.
Histopathology image segmentation is essential for delineating tissue structures in skin cancer
diagnostics, but modeling spatial context and inter-tissue relationships remains a challenge, especially
in regions with overlapping or morphologically similar tissues. Current convolutional neural network
(CNN)-based approaches operate primarily on visual texture, often treating tissues as independent
regions and failing to encode biological context. To this end, we introduce Neural Tissue Relation
Modeling (NTRM), a novel segmentation framework that augments CNNs with a tissue-level graph neural
network to model spatial and functional relationships across tissue types. NTRM constructs a graph over
predicted regions, propagates contextual information via message passing, and refines segmentation
through spatial projection. Unlike prior methods, NTRM explicitly encodes inter-tissue dependencies,
enabling structurally coherent predictions in boundary-dense zones. On the benchmark Histopathology
Non-Melanoma Skin Cancer Segmentation Dataset, NTRM outperforms state-of-the-art methods, achieving a
robust Dice similarity coefficient that is 4.9\% to 31.25\% higher than the best-performing models among
the evaluated approaches. Our experiments indicate that relational modeling offers a principled path
toward more context-aware and interpretable histological segmentation, compared to local receptive-field
architectures that lack tissue-level structural awareness.
BibTeX:
@inproceedings{venkatraman2026can,
title={Can We Go Beyond Visual Features? Neural Tissue Relation Modeling for Relational Graph Analysis in Non-Melanoma Skin Histology},
author={Venkatraman, Shravan and Kavitha, Muthu Subash and Manikandarajan, V and Wu, Jia and others},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={6427--6437},
year={2026}
}
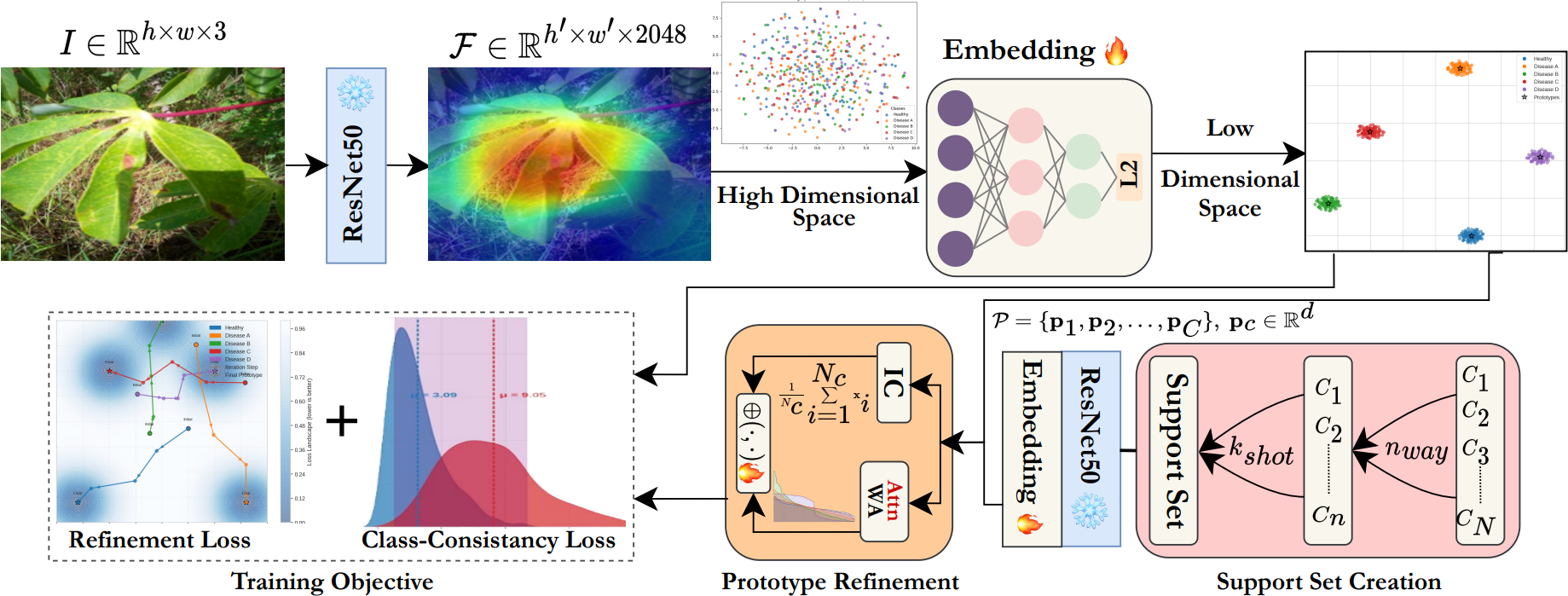
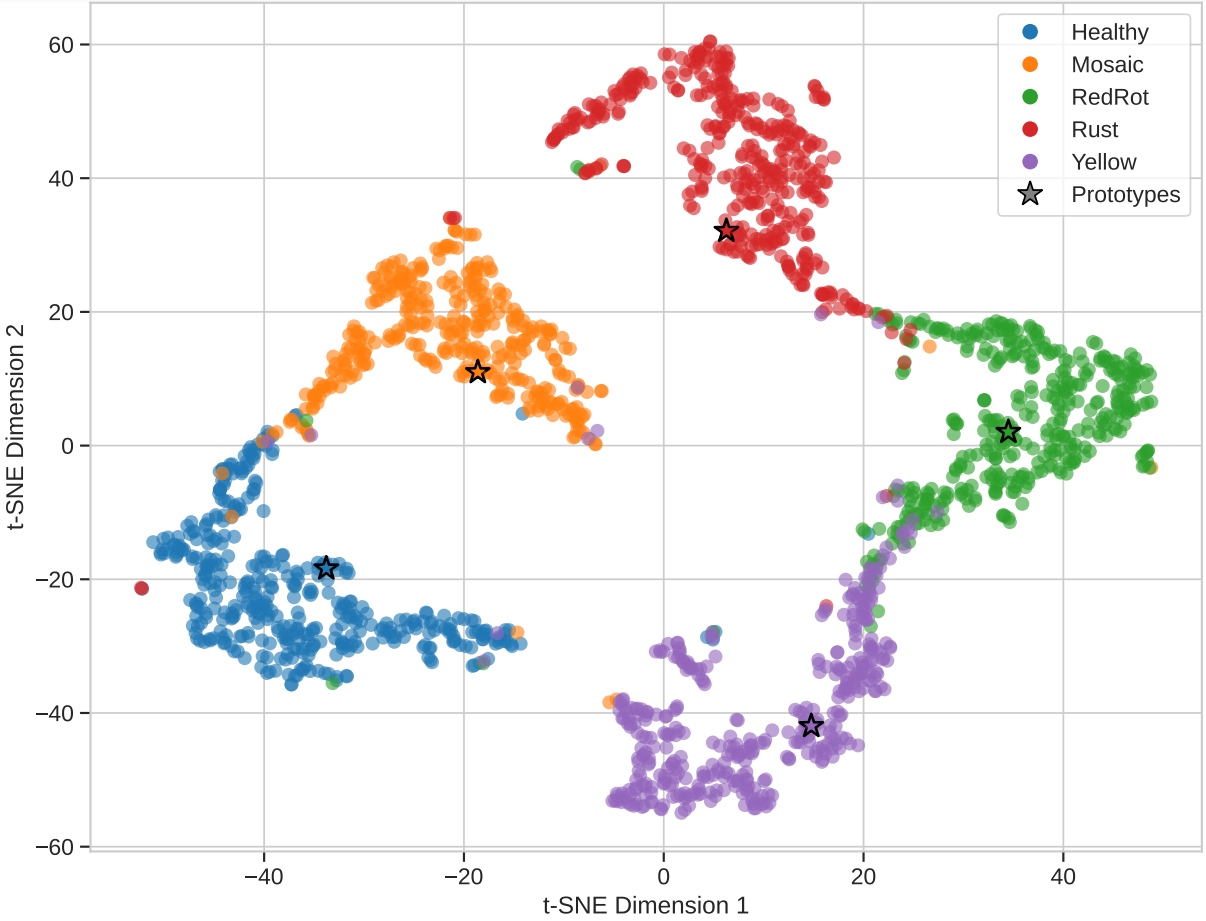
SPROUT: Symptom-centric Prototypical Representation Optimization and Uncertainty-aware Tuning for Few-Shot Precision Agriculture
Neurocomputing
Dynamically weighting symptom-representative samples enhances
few-shot plant disease recognition in
regionally diverse scenarios.
Plant disease detection using computer vision has significantly advanced precision agriculture, but
adapting to new disease variants with minimal labeled examples remains a challenge, particularly when
regional factors influence symptom expression. Current approaches primarily rely on transfer learning or
data augmentation techniques, which often fail to adequately capture the intricate visual
characteristics specific to plant diseases from limited examples. We introduce SPROUT (Symptom-centric
Prototypical Representation Optimization and Uncertainty-aware Tuning), a few-shot learning framework
that leverages an attention-weighted prototype refinement mechanism to identify and emphasize the most
informative disease features in support examples.
BibTeX:
@article{venkatraman2025sprout,
title={SPROUT: Symptom-centric Prototypical Representation Optimization and Uncertainty-aware Tuning for few-shot precision agriculture},
author={Venkatraman, Shravan and Kumar, S Pavan and Pandiyaraju, V and Abeshek, A and Aravintakshan, SA},
journal={Neurocomputing},
pages={132137},
year={2025},
publisher={Elsevier}
}
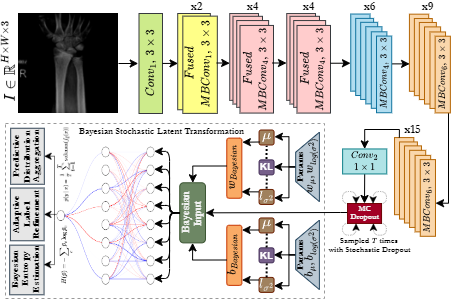
Bayesian Uncertainty Propagation for Bone Fracture Diagnosis via
Region-Aware Adaptive Label
Refinement
Under Review
Entropy-guided label pruning and region-aware uncertainty estimation
enables fracture diagnosis models to
reason under ambiguity.
Radiographic imaging is crucial for diagnosing bone fractures, but the absence of reliable uncertainty
measures in existing models complicates the interpretation of ambiguous cases, especially in complex or
noisy datasets. Current deep learning methods for fracture diagnosis such as convolutional neural
networks (CNNs) and Transformers have improved detection accuracy, but typically rely on deterministic
outputs that fail to estimate predictive confidence or handle mislabeled samples. We introduce BONE-ULR,
a Bayesian approach for bone fracture diagnosis that integrates adaptive label refinement and
spatially-aware uncertainty estimation to enhance both reliability and interpretability. Unlike existing
approaches which provide binary predictions without insight into their confidence or failure cases,
BONE-ULR produces a predictive distribution via multiple stochastic forward passes, enabling effective
quantification of epistemic uncertainty and identification of ambiguous regions. Additionally, we
introduce a dynamic label refinement strategy that ranks training samples by entropy and excludes
high-uncertainty bone X-rays from supervision, mitigating the impact of mislabels and ambiguous fracture
patterns while improving representation learning. Extensive experimental analysis validates that our
approach significantly improves classification accuracy and calibration, achieving an F1-score of 85.91%
and an Expected Calibration Error (ECE) of 0.141, surpassing state-of-the-art (SOTA) methods in both
performance and reliability.
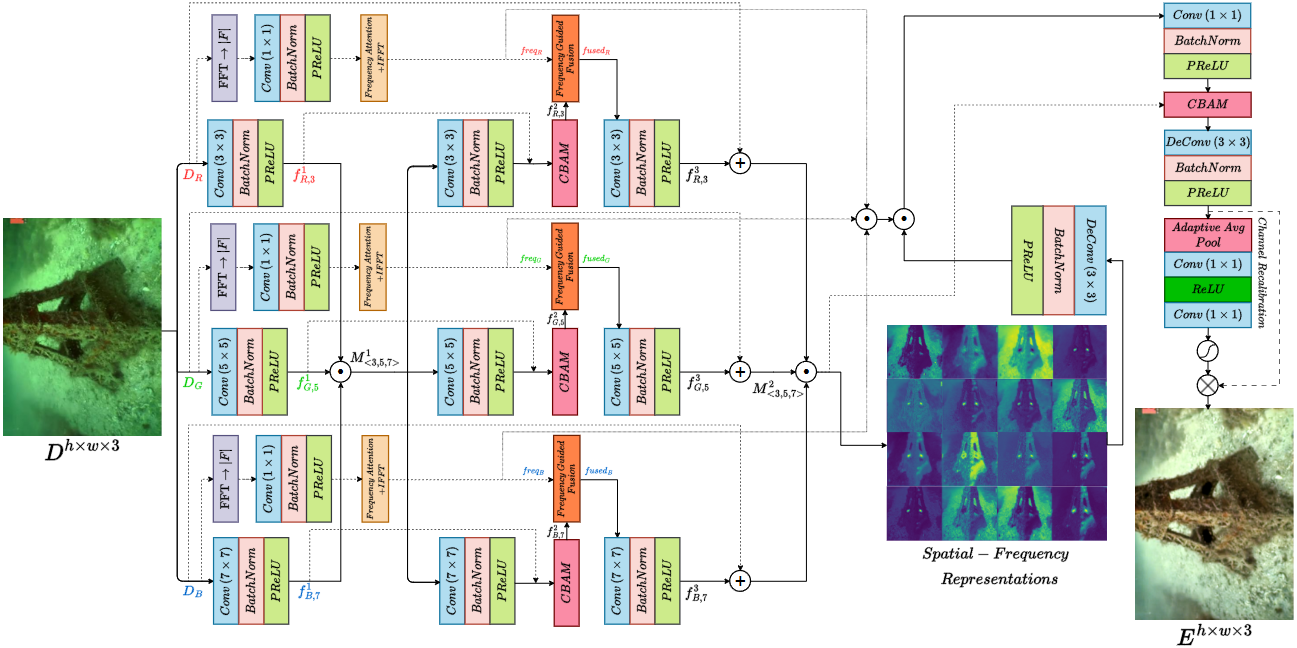
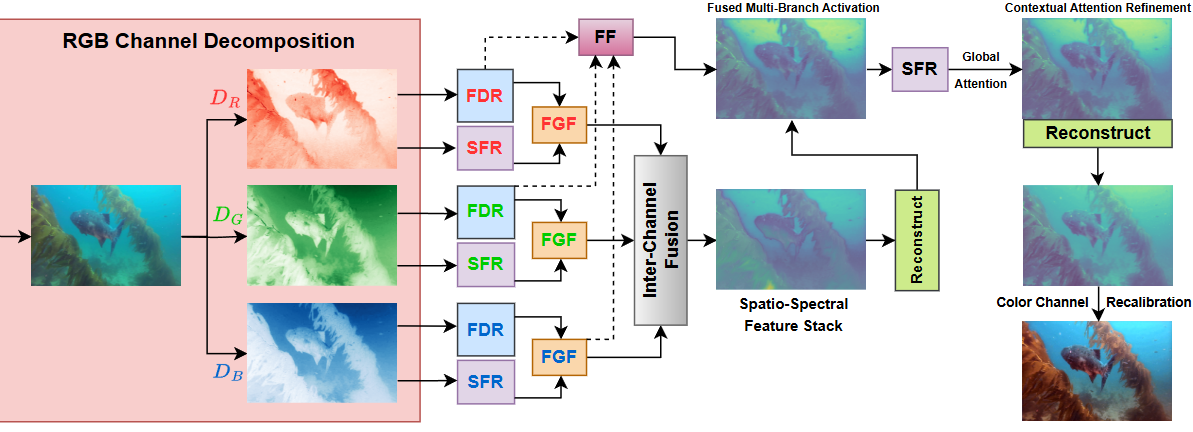
Underwater images suffer from severe degradations, including color distortions, reduced visibility, and
loss of structural details due to wavelength-dependent attenuation and scattering. Existing enhancement
methods primarily focus on spatial-domain processing, neglecting the frequency domain's potential to
capture global color distributions and long-range dependencies. To address these limitations, we propose
FUSION, a dual-domain deep learning framework that jointly leverages spatial and frequency domain
information. FUSION independently processes each RGB channel through multi-scale convolutional kernels
and adaptive attention mechanisms in the spatial domain, while simultaneously extracting global
structural information via FFT-based frequency attention. A Frequency Guided Fusion module integrates
complementary features from both domains, followed by inter-channel fusion and adaptive channel
recalibration to ensure balanced color distributions. Extensive experiments on benchmark datasets (UIEB,
EUVP, SUIM-E) demonstrate that FUSION achieves state-of-the-art performance, consistently outperforming
existing methods in reconstruction fidelity (highest PSNR of 23.717 dB and SSIM of 0.883 on UIEB),
perceptual quality (lowest LPIPS of 0.112 on UIEB), and visual enhancement metrics (best UIQM of 3.414
on UIEB), while requiring significantly fewer parameters (0.28M) and lower computational complexity,
demonstrating its suitability for real-time underwater imaging applications.
BibTeX:
@InProceedings{FUSION,
author = {Jaskaran Singh Walia and Shravan Venkatraman and Pavithra LK},
title = {FUSION: Frequency-guided Underwater Spatial Image recOnstructioN},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops},
month = {June},
year = {2025}
}
Making NeRF See Structure, Not Just Light: Enforcing PDE-Based
Surface Constraints for 3D
Consistency
Bachelor's Thesis
Enforcing physical surface properties through PDE constraints yields
geometrically accurate neural scene
representations from sparse views.
Neural Radiance Fields (NeRFs) have transformed novel view synthesis, but achieving accurate surface
geometry remains challenging, especially with sparse views. Current approaches either require dense
viewpoint sampling or produce inconsistent geometry due to their reliance on purely photometric
supervision. We introduce PDE-NeRF, a physics-informed optimization framework that enforces geometric
consistency through Partial Differential Equation (PDE)-constrained density gradients. Unlike existing
methods that use auxiliary losses, our approach directly shapes the underlying density field by aligning
spatial derivatives with ground-truth surface normals. We combine this with an efficient hash-based
encoding scheme to enable high-fidelity reconstruction from sparse views. Our model achieves up to 8.51
dB higher PSNR and a 0.062 reduction in LPIPS over NeRF-based baselines, demonstrating superior
perceptual quality. PDE-NeRF maintains consistent surface details, even in areas visible from only 30–40
views in a 360-degree capture, effectively addressing a key challenge in neural scene reconstruction.
Experiments on diverse synthetic scenes demonstrate that our method achieves superior geometric accuracy
and visual quality, outperforming existing approaches across both 360° inward-facing and LLFF datasets.
BibTeX:
NEED TO ADD BIBTEX
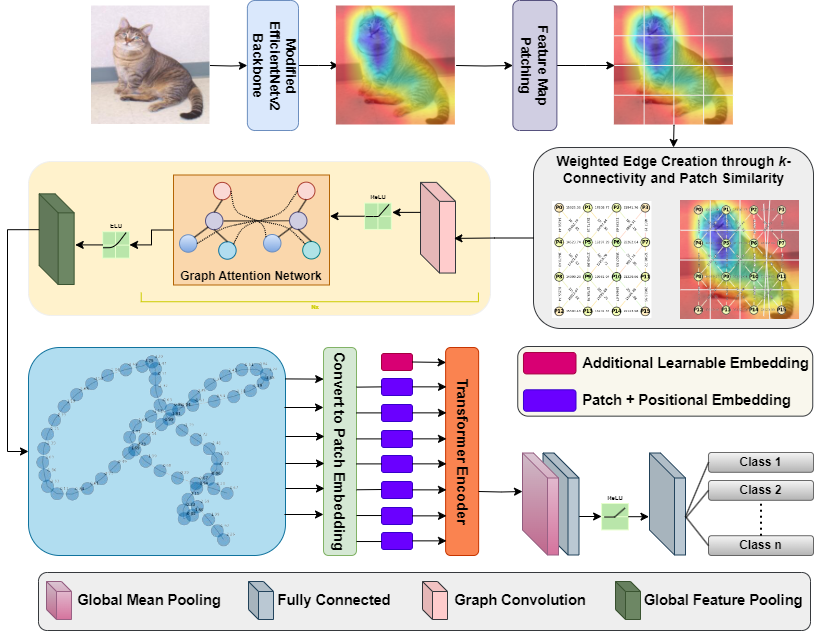
SAG-ViT: A Scale-Aware, High-Fidelity Patching Approach with Graph
Attention for Vision
Transformers
Complex and Intelligent Systems
Structuring attention through multi-scale graphs enable transformers
to reason across visual hierarchies.
Vision Transformers (ViTs) have redefined image classification by leveraging self-attention to capture
complex patterns and long-range dependencies between image patches. However, a key challenge for ViTs is
efficiently incorporating multi-scale feature representations, which is inherent in convolutional neural
networks (CNNs) through their hierarchical structure. Graph transformers have made strides in addressing
this by leveraging graph-based modeling, but they often lose or insufficiently represent spatial
hierarchies, especially since redundant or less relevant areas dilute the image's contextual
representation. To bridge this gap, we propose SAG-ViT, a Scale-Aware Graph Attention ViT that
integrates multi-scale feature capabilities of CNNs, representational power of ViTs, and graph-attended
patching to enable richer contextual representation. Using EfficientNetV2 as a backbone, the model
extracts multi-scale feature maps, dividing them into patches to preserve richer semantic information
compared to directly patching the input images. The patches are structured into a graph using spatial
and feature similarities, where a Graph Attention Network (GAT) refines the node embeddings. This
refined graph representation is then processed by a Transformer encoder, capturing long-range
dependencies and complex interactions. We evaluate SAG-ViT on benchmark datasets across various domains,
validating its effectiveness in advancing image classification tasks. Our code and weights are available
at https://github.com/shravan-18/SAG-ViT.
BibTeX:
@misc{SAGViT,
title={SAG-ViT: A Scale-Aware, High-Fidelity Patching Approach with Graph Attention for Vision Transformers},
author={Shravan Venkatraman and Jaskaran Singh Walia and Joe Dhanith P R},
year={2025},
eprint={2411.09420},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.09420},
}
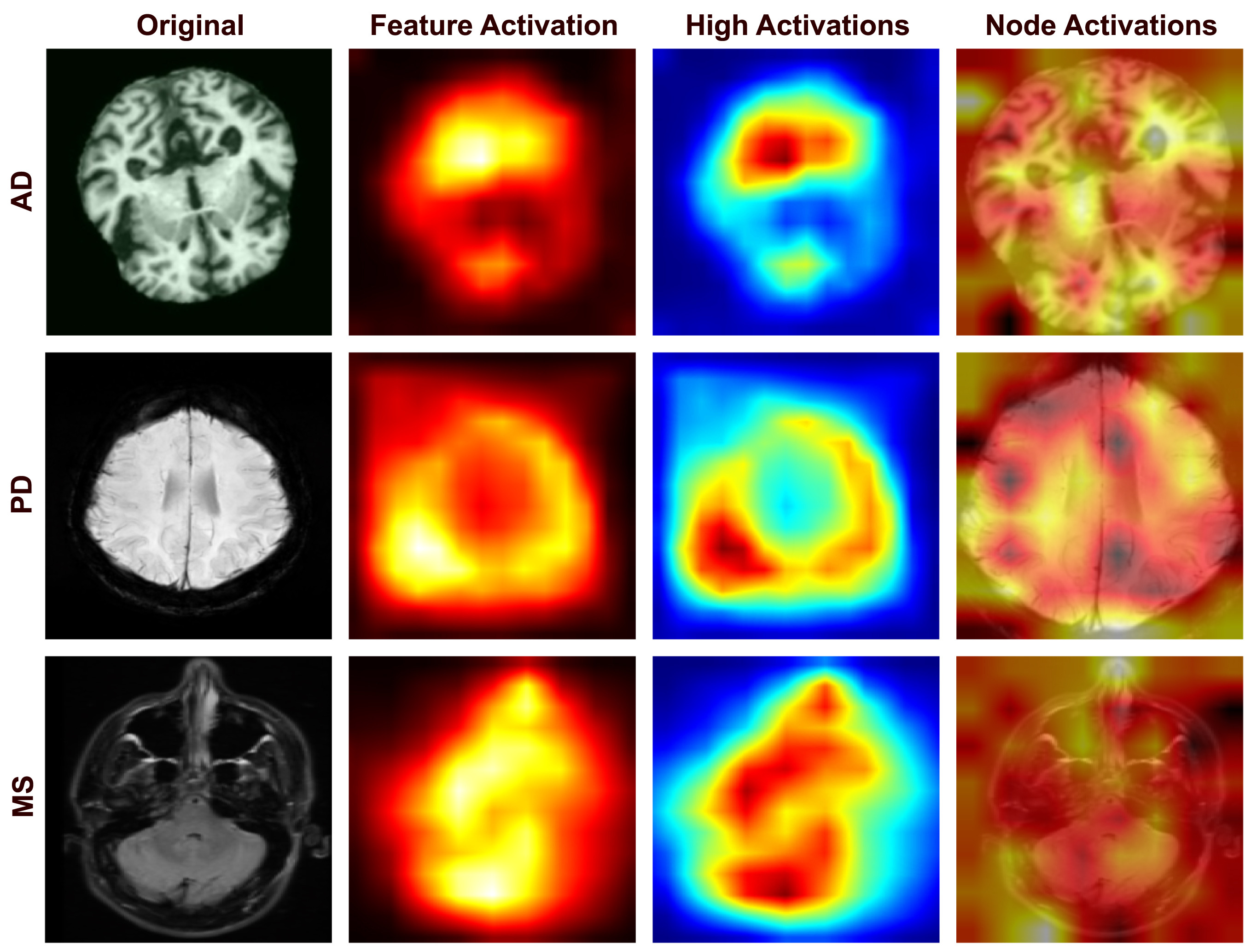
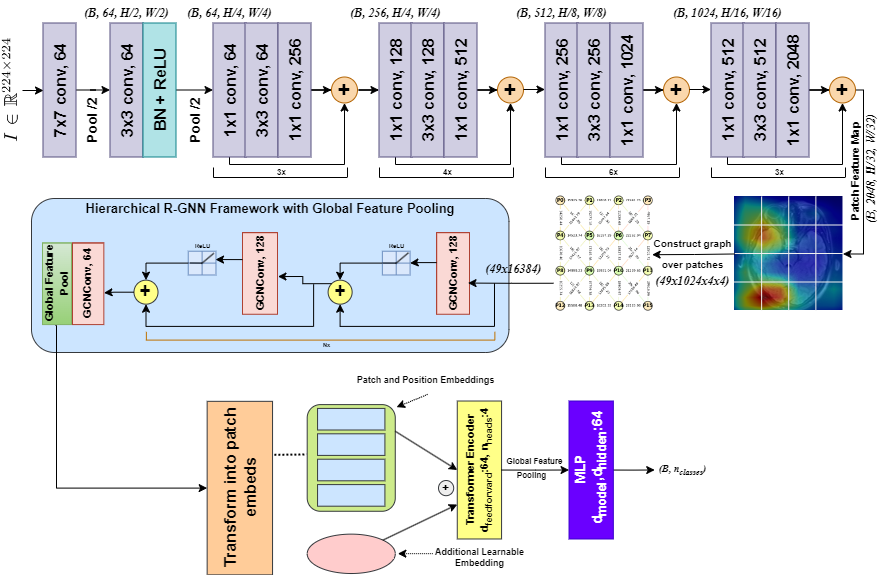
Hierarchical Graph-Guided Contextual Representation Learning for
Neurodegenerative Pattern
Recognition in MRI
Computers in Biology and Medicine
Bridging local-global brain patterns and transforming disconnected
MRI patches into spatially-coherent
disease markers through residual graphs.
Neurodegenerative (ND) diseases are autoimmune diseases that affect the central nervous system,
including the brain and spinal cord. In recent years, deep learning has demonstrated its potential in
medical imaging for diagnostic purposes. However, for these techniques to be fully accepted in clinical
settings, they must achieve high performance and gain the confidence of medical professionals regarding
their interpretability. Therefore, an interpretable model should make decisions based on clinically
relevant information like a domain expert. To achieve this, we present an interpretable classifier
dedicated to the most common autoimmune ND diseases. The lesions associated with ND diseases exhibit
irregular distributions and spatial dependencies in different regions of the brain, challenging
traditional models to effectively capture both local and global relationships. To address this issue, we
present a Residual Graph Neural Network enhanced Vision Transformer (RG-ViT) that represents MRI data as
a graph of interconnected patches. By integrating residual connections into the GNN framework, we
preserve critical features while promoting effective message passing. This approach overcomes the
problem of spatial disconnection prevalent in standard patch-based methods and provides a cohesive and
context-aware analysis of MRI data. Experimental results in detecting multiple sclerosis (MS),
Parkinson's (PD), and Alzheimer's disease (AD) demonstrated our approach's consistent accuracy scores of
98.7%, 99.6%, and 99.1%, respectively. On the combined dataset for the global classification of ND
diseases, it achieved an F1 score of 99.2%, justifying its generalizability.
BibTeX:
@article{RGViT,
title = {Hierarchical graph-guided contextual representation learning for Neurodegenerative pattern recognition in MRI},
journal = {Computers in Biology and Medicine},
volume = {199},
pages = {111276},
year = {2025},
issn = {0010-4825},
doi = {https://doi.org/10.1016/j.compbiomed.2025.111276},
url = {https://www.sciencedirect.com/science/article/pii/S0010482525016300},
author = {Shravan Venkatraman and Joe Dhanith P.R. and Muthu Subash Kavitha},
}
2024
Targeted Neural Architectures in Multi-Objective Frameworks for
Complete Glioma Characterization from
Multimodal MRI
Under Review
Augmenting encoder-decoder architectures with attention-guided
feature extraction helps in highly
effective localization, segmentation, and classification of brain tumors.
Tumors in the brain are caused by abnormal growths in brain tissue resulting from different types of
brain cells. If undiagnosed, they lead to aggressive neurological deficits, including cognitive
impairment, motor dysfunction, and sensory loss. With the growth of the tumor, intracranial pressure
will definitely increase, and this may bring about such dramatic complications as herniation of the
brain, which may be fatal. Hence, early diagnosis and treatment are required to control the
complications arising due to such tumors to retard their growth. Several works related to deep learning
(DL) and artificial intelligence (AI) are being conducted to help doctors diagnose at an early stage by
using the scans taken from Magnetic Resonance Imaging (MRI). Our research proposes targeted neural
architectures within multi-objective frameworks that can localize, segment, and classify the grade of
these gliomas from multimodal MRI images to solve this critical issue. Our localization framework
utilizes a targeted architecture that enhances the LinkNet framework with an encoder inspired by VGG19
for better multimodal feature extraction from the tumor along with spatial and graph attention
mechanisms that sharpen feature focus and inter-feature relationships. For the segmentation objective,
we deployed a specialized framework using the SeResNet101 CNN model as the encoder backbone integrated
into the LinkNet architecture, achieving an IoU Score of 96%. The classification objective is addressed
through a distinct framework implemented by combining the SeResNet152 feature extractor with Adaptive
Boosting classifier, reaching an accuracy of 98.53%. Our multi-objective approach with targeted neural
architectures demonstrated promising results for complete glioma characterization, with the potential to
advance medical AI by enabling early diagnosis and providing more accurate treatment options for
patients.
BibTeX:
@misc{v2024integrateddeeplearningframework,
title={An Integrated Deep Learning Framework for Effective Brain Tumor Localization, Segmentation, and Classification from Magnetic Resonance Images},
author={Pandiyaraju V and Shravan Venkatraman and Abeshek A and Aravintakshan S A and Pavan Kumar S and Madhan S},
year={2024},
eprint={2409.17273},
archivePrefix={arXiv},
primaryClass={eess.IV},
url={https://arxiv.org/abs/2409.17273},
}
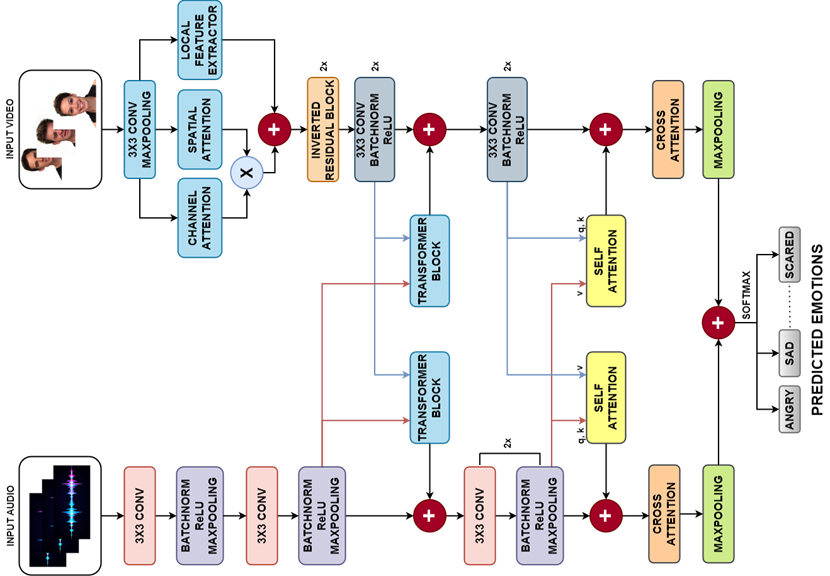
Multimodal Emotion Recognition using Audio-Video Transformer Fusion
with Cross Attention
Under Review
Cross-modal attention enables synchronized audio-visual feature
extraction through Transformer fusion for
emotion recognition.
Understanding emotions is a fundamental aspect of human communication. Integrating audio and video
signals offers a more comprehensive understanding of emotional states compared to traditional methods
that rely on a single data source, such as speech or facial expressions. Despite its potential,
multimodal emotion recognition faces significant challenges, particularly in synchronization, feature
extraction, and fusion of diverse data sources. To address these issues, this paper introduces a novel
transformer-based model named Audio-Video Transformer Fusion with Cross Attention (AVT-CA). The AVT-CA
model employs a transformer fusion approach to effectively capture and synchronize interlinked features
from both audio and video inputs, thereby resolving synchronization problems. Additionally, the Cross
Attention mechanism within AVT-CA selectively extracts and emphasizes critical features while discarding
irrelevant ones from both modalities, addressing feature extraction and fusion challenges. Extensive
experimental analysis conducted on the CMU-MOSEI, RAVDESS and CREMA-D datasets demonstrates the efficacy
of the proposed model. The results underscore the importance of AVT-CA in developing precise and
reliable multimodal emotion recognition systems for practical applications.
BibTeX:
@misc{AVTCA,
title={Multimodal Emotion Recognition using Audio-Video Transformer Fusion with Cross Attention},
author={Joe Dhanith P R and Shravan Venkatraman and Vigya Sharma and Santhosh Malarvannan and Modigari Narendra},
year={2025},
eprint={2407.18552},
archivePrefix={arXiv},
primaryClass={cs.MM},
url={https://arxiv.org/abs/2407.18552},
}
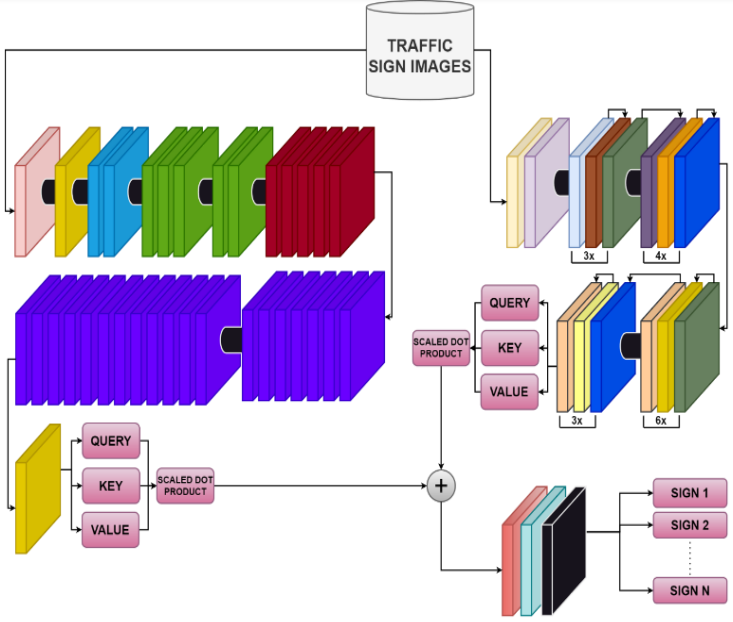
Traffic Sign Classification Using Attention Fused Deep
Convolutional Neural Networks
8\(^{th}\) International Conference on Robotics and Automation
Sciences
(ICRAS)
Attention-fused deep convolutional neural networks improve the
ability to classify diverse traffic signs
through parallel hierarchical and multi-scale feature emphasis.
Autonomous vehicular technology, also known as self-driving or driverless technology, refers to the
innovation that enables vehicles to operate without human intervention. Traffic sign classification
(TSC) is a critical component in autonomous vehicular technology, as it allows vehicles to recognize and
interpret traffic signs, which is essential for safe and rule-compliant navigation. This work proposes a
novel attention-fused deep convolutional neural network (AFDCNN) for TSC. The proposed AFDCNN
incorporates the capabilities of ResNet50 and EfficientNetV2 by combining their outputs through a
self-attention mechanism which enhances its ability to classify traffic signs. Analysis of the GTSRB,
LISA, and MASTIF datasets revealed that the proposed model exhibited superior performance compared to
state-of-the-art models, as evidenced by higher scores in recall, precision, F1-score, and accuracy
metrics.
BibTeX:
@INPROCEEDINGS{ICRAS_TSC,
author={Venkatraman, Shravan and Abeshek, A and Malarvannan, Santhosh and Shriyans, A and Jashwanth, R and Joe Dhanith, P R},
booktitle={2024 8th International Conference on Robotics and Automation Sciences (ICRAS)},
title={Traffic Sign Classification Using Attention Fused Deep Convolutional Neural Network},
year={2024},
volume={},
number={},
pages={90-94},
doi={10.1109/ICRAS62427.2024.10654469}
}
2023
Improved Tomato Leaf Disease Classification Through Adaptive
Ensemble Models with Exponential Moving
Average Fusion and Enhanced Weighted Gradient Optimization
Frontiers in Plant Science
Ensemble deep learning with optimized weighted gradient techniques
enables early and accurate detection of
tomato leaf diseases.
Tomatoes are one of the most widely consumed and economically significant food crops globally, with
their yield quality and quantity significantly impacted by various diseases. Early disease detection is
crucial to reduce their effects and improve crop yields, supporting farmers. While previous research has
applied machine learning techniques to segment and classify tomato leaf images, existing classifiers
often struggle with accurately detecting new disease types. This study proposes a novel approach to
tomato leaf disease classification by harnessing the power of deep learning and swarm intelligence-based
optimization techniques. An ensemble model is developed, integrating an exponential moving average
function with temporal constraints and an enhanced weighted gradient optimizer into fine-tuned Visual
Geometry Group-16 (VGG-16) and Neural Architecture Search Network (NASNet) mobile training methods. The
model is trained and validated on a dataset of 10,000 tomato leaf images categorized into nine disease
classes, with an additional 1,000 images reserved for testing. The results show superior performance
across key metrics: accuracy (98.7%), loss (4%), precision (97.9%), recall (98.6%), receiver operating
characteristic curve (99.97%), and F1-score (98.7%), outperforming existing methods and enhancing
disease detection accuracy.
BibTeX:
@ARTICLE{10.3389/fpls.2024.1382416,
AUTHOR={V., Pandiyaraju and Kumar, A. M. Senthil and Praveen, Joe I. R. and Venkatraman, Shravan and Kumar, S. Pavan and Aravintakshan, S. A. and Abeshek, A. and Kannan, A. },
TITLE={Improved tomato leaf disease classification through adaptive ensemble models with exponential moving average fusion and enhanced weighted gradient optimization},
JOURNAL={Frontiers in Plant Science},
VOLUME={15},
YEAR={2024},
URL={https://www.frontiersin.org/journals/plant-science/articles/10.3389/fpls.2024.1382416},
DOI={10.3389/fpls.2024.1382416},
ISSN={1664-462X},
}