My research focuses on developing self-evolving large multimodal models for generalizable multimodal
intelligence, within the broader context of multimodal representation
learning for reasoning. I also work on unified large-scale models for image understanding and
generation, and (on the side) I'm interested in geometry-aware representations and neural
rendering for computer graphics.
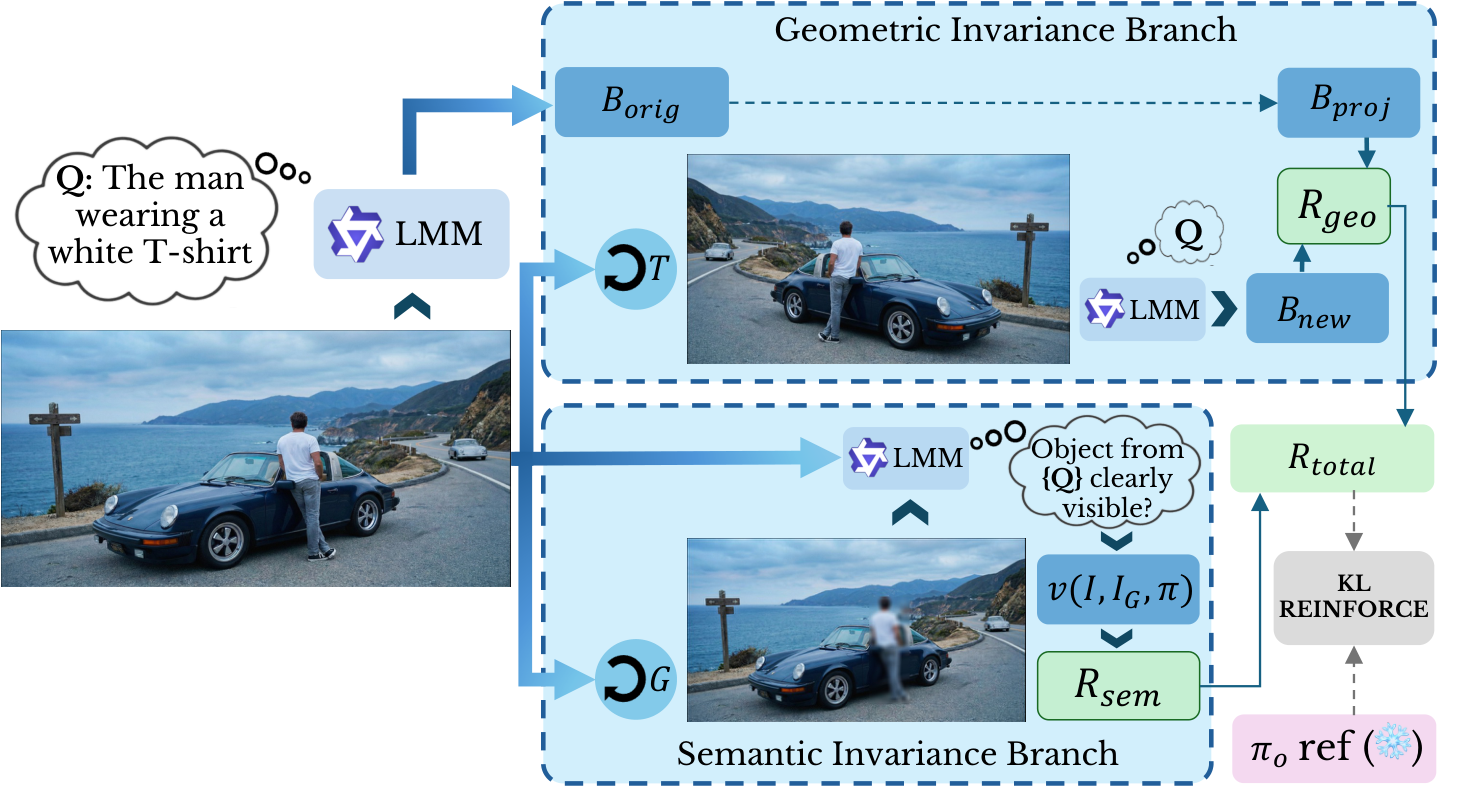
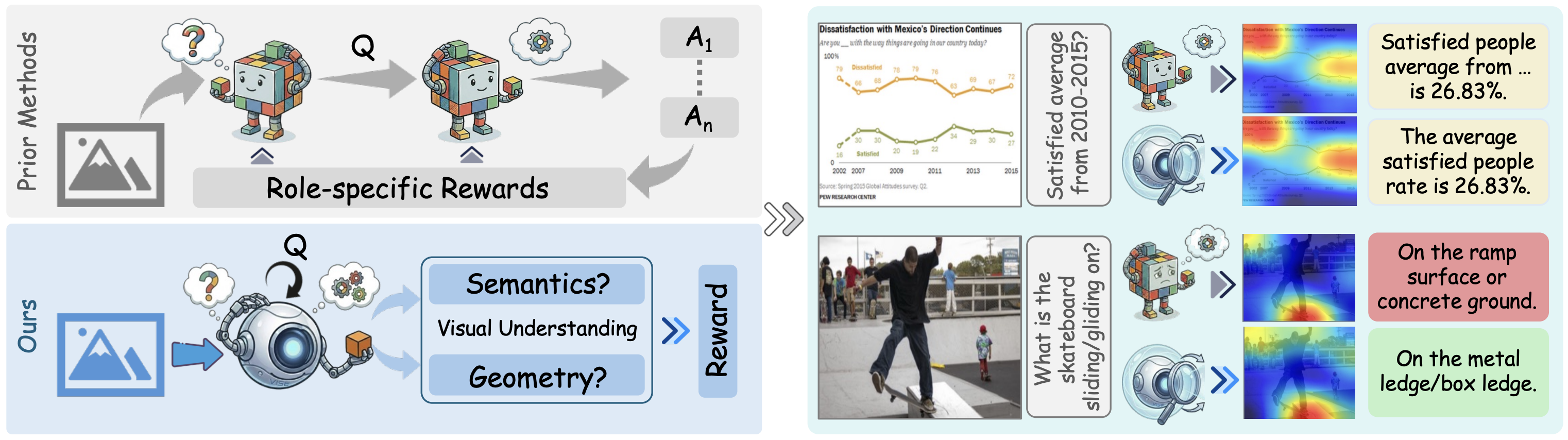
Recently, self-evolving large multimodal models (LMMs) have received attention for improving visual reasoning in a purely unsupervised setting. However, multi-role self-play and self-consistency reward schemes in existing self-evolving LMMs optimize answer agreement without ensuring the decoder attends to visual content, relying instead on statistical language priors to produce self consistent outputs. This leads to a persistent failure mode we term visual under-conditioning, where the decoder relies on language priors rather than the image during generation, manifesting as insufficient attention to visual tokens. As a result, current self-evolving LMMs struggle on vision--language understanding tasks such as image captioning and visual question answering. To address this, we propose VISE (Visual Invariance Self-Evolution), a purely unsupervised self-evolving framework that directly regularizes the model's visual conditioning policy through two complementary invariance-based rewards: a geometric invariance reward that enforces spatial consistency under known transformations, and a semantic invariance reward that penalizes evidence-agnostic generation by requiring the model to recognize the absence of evidence when predicted regions are perturbed. VISE operates within a single model without specialist roles, external reward models, or annotations, and is trained on raw unlabeled images. Experiments on 18 benchmarks demonstrate the efficacy of our approach. Using Qwen3-VL-2B as the base model, VISE achieves gains of +16.85 CIDEr on COCO and +19.66 CIDEr on TextCaps, reduces object hallucination by 5.0 Chair-I points, and generalizes across four model families and scales.
BibTeX:
@inproceedings{venkatraman2026vise,
title = {Paying More Attention to Visual Tokens in Self-Evolving Large Multimodal Models},
author = {Venkatraman, Shravan and Thawkar, Ritesh and Thawakar, Omkar and
Anwer, Rao Muhammad and Cholakkal, Hisham and Khan, Salman and Khan, Fahad Shahbaz},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2026}
}
Ask, Solve, Generate: Self-Evolving Unified Multimodal
Understanding and Generation via Self-Consistency Rewards
arXiv
A unified multimodal model that self-improves both image
understanding and generation from unlabeled images, using only self-consistency rewards.
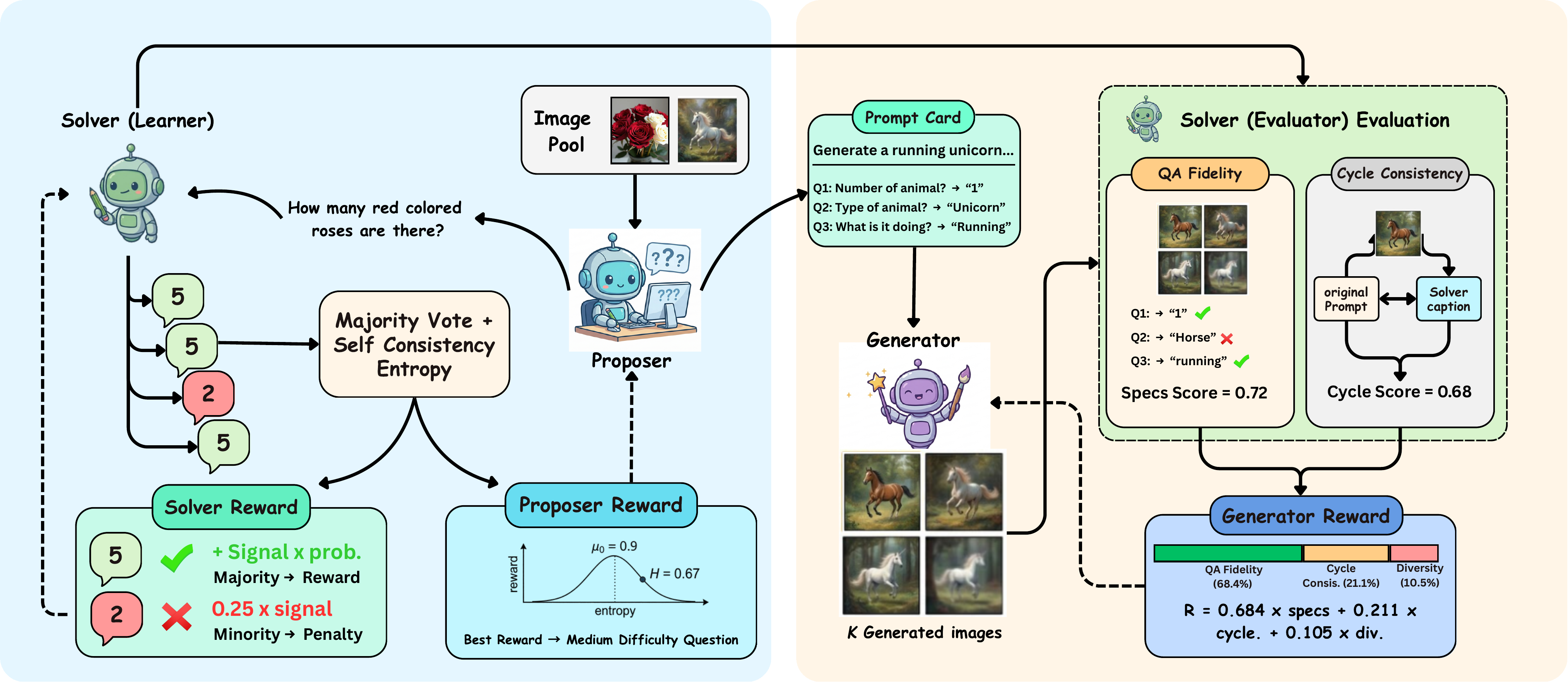
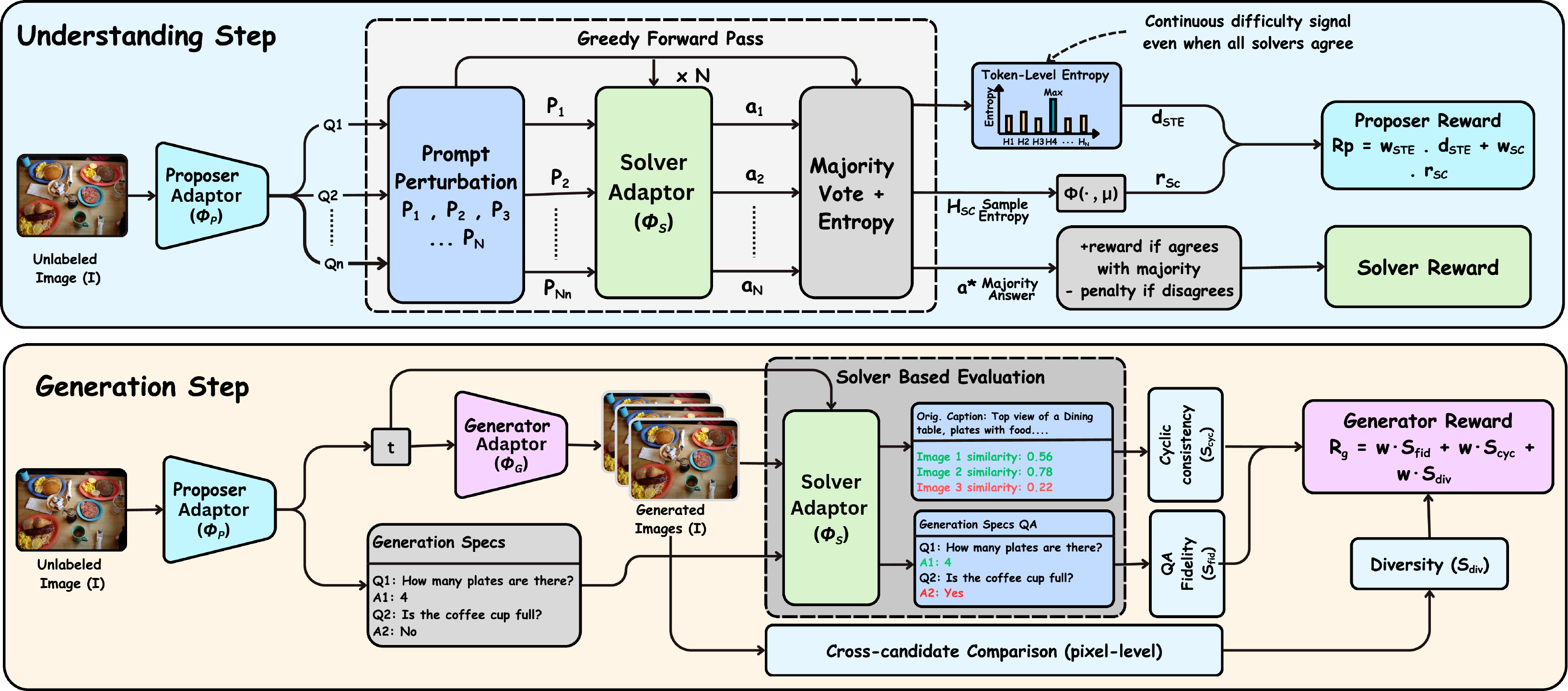
Most unified large multimodal models (LMMs) that support both visual understanding and image generation still rely on curated post-training supervision, such as human annotations, preference labels, or external reward models. We ask whether a unified LMM can improve both abilities autonomously using only unlabeled images. We propose a self-evolving training framework with three internal roles: a Proposer that generates visual questions, a Solver that answers and evaluates them, and a Generator that synthesizes images. Training uses only self-derived consistency signals, without human annotations, preference labels, or task-trained external reward/judge models. To stabilize learning, we introduce Solver Token Entropy (STE), a continuous difficulty signal based on token-level prediction uncertainty that remains useful even when sample-level consistency becomes unreliable. For image generation, we design a multi-scale internal evaluation scheme that combines question-answer fidelity scoring with cycle-consistent captioning. This creates a solver-mediated coupling, where better visual understanding enables more reliable generation assessment and stronger internal training signals. The framework preserves the same role decomposition, reward logic, and training schedule across diffusion-based BLIP3o, rectified-flow BAGEL, and autoregressive VARGPT-v1.1 architectures, requiring only each backbone's native prompting and generation interface. Across eight understanding metrics, our method consistently improves over the corresponding base models. On BAGEL, it achieves a +3.5% absolute gain on MMMU and improves GenEval image generation performance from 82% to 85%.
BibTeX:
@article{thawkar2026asksolvegenerate,
title={Ask, Solve, Generate: Self-Evolving Unified Multimodal Understanding and Generation via Self-Consistency Rewards},
author={Thawkar, Ritesh and Venkatraman, Shravan and Thawakar, Omkar and Shaker, Abdelrahman and Khan, Fahad and Cholakkal, Hisham and Khan, Salman and Anwer, Rao Muhammad},
journal={arXiv preprint arXiv:2606.27376},
year={2026}
}
EvoLMM: Self-Evolving Large Multimodal Models with Continuous
Rewards
arXiv
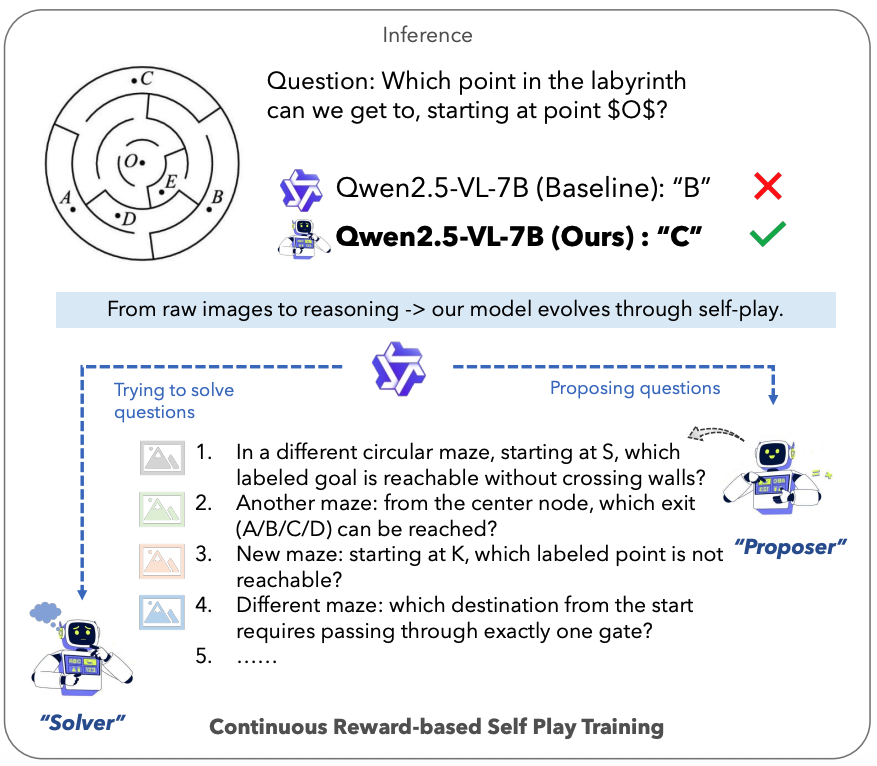
EvoLMM is a fully unsupervised self-evolving framework for
large multimodal models (LMMs) that
improves visual reasoning from raw images only by coupling a Proposer and a Solver trained via
continuous self-consistency rewards.
Recent advances in large multimodal models (LMMs) have enabled impressive reasoning and perception
abilities, yet most existing training pipelines still depend on human-curated data or externally
verified reward models, limiting their autonomy and scalability. In this work, we strive to
improve LMM reasoning capabilities in a purely unsupervised fashion (without any annotated data or
reward distillation). To this end, we propose a self-evolving framework, named EvoLMM, that
instantiates two cooperative agents from a single backbone model: a Proposer, which generates
diverse, image-grounded questions, and a Solver, which solves them through internal consistency,
where learning proceeds through a continuous self-rewarding process. This dynamic feedback
encourages both the generation of informative queries and the refinement of structured reasoning
without relying on ground-truth or human judgments. When using the popular Qwen2.5-VL as the base
model, our EvoLMM yields consistent gains up to ∼3% on multimodal math-reasoning benchmarks,
including ChartQA, MathVista, and MathVision, using only raw training images. We hope our simple
yet effective approach will serve as a solid baseline easing future research in self-improving
LMMs in a fully unsupervised fashion.
BibTeX:
@misc{thawakar2025evolmmselfevolvinglargemultimodal,
title={EvoLMM: Self-Evolving Large Multimodal Models with Continuous Rewards},
author={Omkar Thawakar and Shravan Venkatraman and Ritesh Thawkar and Abdelrahman Shaker and Hisham Cholakkal and Rao Muhammad Anwer and Salman Khan and Fahad Khan},
year={2025},
eprint={2511.16672},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2511.16672},
}