|
I am an M.Sc. computer vision student at MBZUAI. I am fortunate to be a part of the Intellectual and Visual Analytics Lab, where I am advised by Dr. Fahad Khan and Dr. Salman Khan. I completed my undergrad in computer science at VIT University, advised by Dr. Joe Dhanith and Dr. Pandiyaraju (also receiving the Sir C. V. Raman Award three times during my time there). My research focuses on developing self-evolving large multimodal models for generalizable multimodal intelligence, within the broader context of multimodal representation learning for reasoning. I also work on unified large-scale models for image understanding and generation, with a focus on geometry-aware representations and neural rendering in computer graphics. Prior to this, I was a research intern at Nagasaki University advised by Dr. Muthu Subash Kavitha. In the summer of 2024, I interned at MedxAI under the mentorship of Dr. Susan Elias and Dr. Sheena Pravin. I also work on industry- and consultancy-funded projects through SPORIC at VIT. I'm always happy to chat about research, collaborations, or startups — feel free to send me an email! :) |

|
|
|
Hover over publications for quick preview |
|
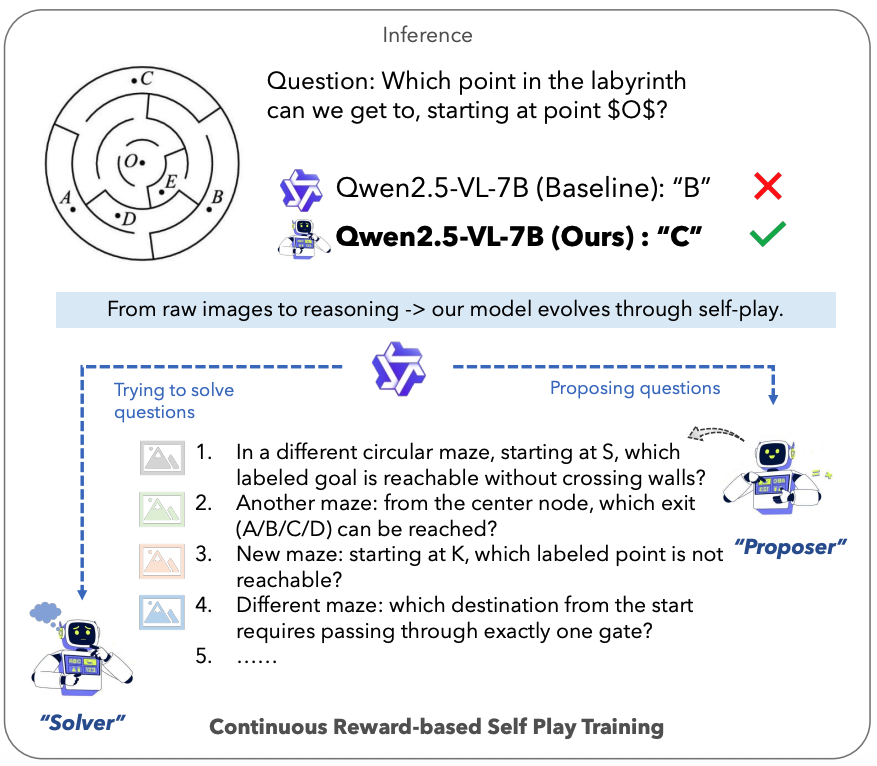
Omkar Thawakar*, Shravan Venkatraman*, Ritesh Thawkar*, Abdelrahman M Shaker, Hisham Cholakkal, Rao Muhammad Anwer, Salman Khan, Fahad Shahbaz Khan arXiv paper / code / project page / abs / bibtex EvoLMM is a fully unsupervised self-evolving framework for large multimodal models (LMMs) that improves visual reasoning from raw images only by coupling a Proposer and a Solver trained via continuous self-consistency rewards. |
|

Making NeRF See Structure, Not Just Light: Enforcing
PDE-Based Surface Constraints
Pattern Recognition
|
Shravan Venkatraman, Pandiyaraju V Pattern Recognition code & paper: out soon Enforcing physical surface properties through PDE constraints yields geometrically accurate neural scene representations from sparse views. |
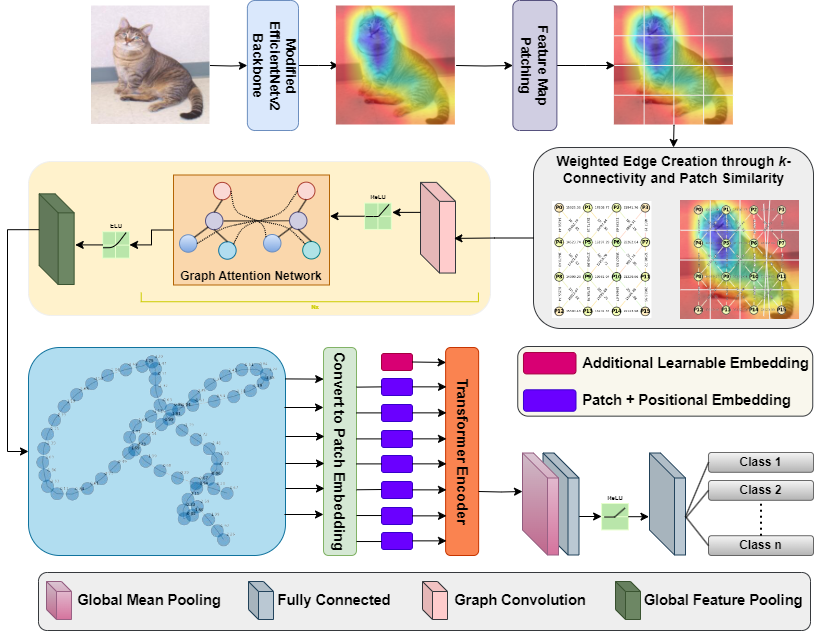
SAG-ViT: A Scale-Aware, High-Fidelity Patching Approach with
Graph Attention
Complex and Intelligent Systems
|
Shravan Venkatraman, Jaskaran Singh Walia, Joe Dhanith P R Complex and Intelligent Systems code / paper / Hugging Face Structuring attention through multi-scale graphs enable transformers to reason across visual hierarchies. |
|
|

|
|
Last updated January 2026. |